
What Is an Enterprise Knowledge Graph?
The Governance Layer That Makes a Graph "Enterprise-Grade"
Key Takeaways
- An enterprise knowledge graph is a knowledge graph built for enterprise deployment. It adds formal ontology governance, entity resolution across multiple source systems, role-based access controls, and provenance tracking to the core graph model.
- What makes the system ‘enterprise’ is not the graph database itself. It is the continuous reconciliation of meaning, identity, and policy across changing systems at enterprise scale.
- Entity resolution is the most technically demanding component and the most common source of production failure. It is the process of recognizing that the same real-world entity appears under different identifiers and formats across source systems.
- Ontology governance is an ongoing function. Treat it as a one-time project and the implementation will fail to scale.
- Enterprise knowledge graphs earn their cost in environments that need multi-hop reasoning across many connected data sources, particularly in regulated industries where explainability and auditability are non-negotiable.
- An enterprise knowledge graph is not the right choice everywhere. Where query patterns are stable, entity types are few, and source systems are well-structured, a relational data warehouse delivers better return at lower cost.
What is an enterprise knowledge graph?
An enterprise knowledge graph is a knowledge graph built for enterprise deployment. It applies the graph model to an enterprise's own data, adds a formal ontology, and is designed to stay accurate as systems, teams, and business definitions change.
The concept of the knowledge graph gained mainstream recognition when Google applied it at web scale in 2012 to surface contextual information in search results. Enterprise knowledge graphs inherit the same structural logic but apply it to an enterprise's own proprietary data. That shift in scope changes the requirements entirely.
A standard knowledge graph maps entities and relationships within a defined domain: a product catalog, a research corpus, a regulatory taxonomy. The domain is bounded, the schema is relatively stable, and governance is typically light. An enterprise knowledge graph applies the same model across the data that runs the business. That creates a different set of requirements: multiple source systems with conflicting definitions, data that updates constantly, access controls that vary by role and jurisdiction, and the need to trace every fact back to its source.
How Ally Built a Modern Fraud Intelligence Platform
Learn how Ally applied graph analytics and contextual investigation tools to uncover complex fraud networks and strengthen fraud prevention.
Read Case Study
The graph itself is not what distinguishes an enterprise knowledge graph. What surrounds it does: a governed ontology that defines shared meaning, an entity resolution process that reconciles the same real-world entity as it appears across different systems, and a governance framework that keeps the graph accurate over time.
Why can't a standard knowledge graph do what an enterprise knowledge graph does?
A standard knowledge graph can represent relationships between entities. Enterprise environments add a harder problem: maintaining shared meaning, consistency, and traceability across fragmented systems, teams, and regulatory domains.
A customer may appear as "J. Smith" in one system, "John Smith" in another, and as a numeric identifier elsewhere. A product marked as discontinued in the ERP may still appear as active in the CRM. A conventional knowledge graph can model these inconsistencies. Resolving them consistently across an enterprise requires capabilities beyond graph storage and traversal. Without those controls, the graph reflects the fragmentation of the underlying systems instead of presenting a coherent operational view.
In regulated environments, that distinction matters. A misidentified entity can produce an incorrect risk score, trigger the wrong compliance alert, or connect a transaction to the wrong counterparty.
Enterprise knowledge graph deployments typically add three operational capabilities:
- A governed ontology that defines shared business meaning across the enterprise.
- Entity resolution that reconciles the same real-world entity across source systems.
- Provenance tracking that records where facts originated and when they were last validated.
Those capabilities also shape how effective enterprise AI becomes. AI systems operating against unresolved or inconsistent enterprise data can produce outputs that appear plausible but are difficult to validate or trace back to authoritative sources. Enterprise knowledge graphs give AI systems a governed and traceable layer of relationships and context rather than relying on probabilistic pattern matching alone.
For regulated industries, that distinction is not academic. It is the difference between an AI-generated recommendation a compliance or investigative team can act on with confidence and one they cannot.

How does an enterprise knowledge graph work?
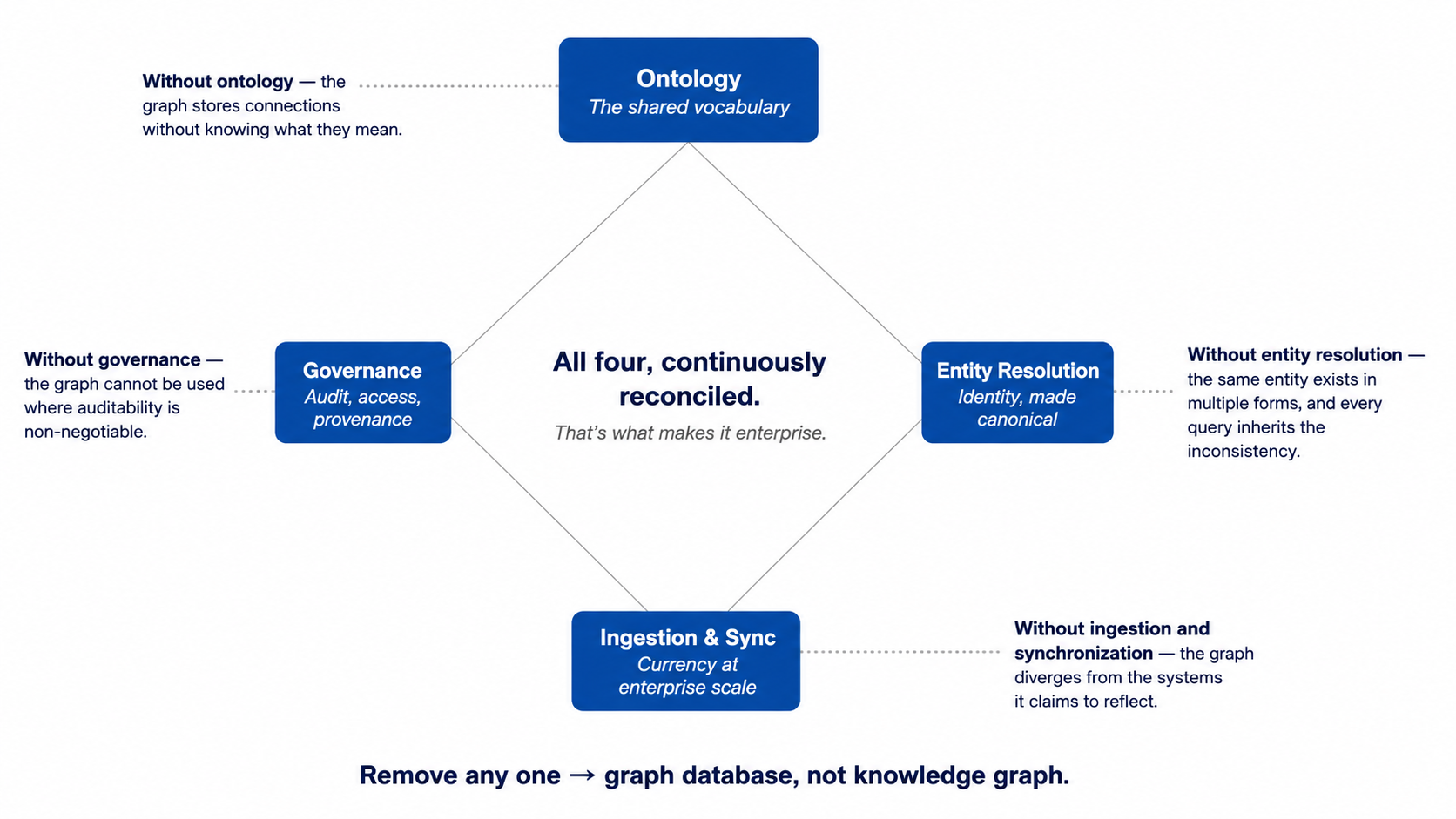
An enterprise knowledge graph works through four interdependent components: an ontology, an entity resolution process, ingestion pipelines, and a governance layer.
Think of a building registry that tracks not just addresses but which properties belong to the same owner, even when registered under different legal entities, and which buildings are subject to the same planning restrictions. The registry is updated continuously, and different users see different levels of detail depending on their access rights. An enterprise knowledge graph works the same way: a maintained, governed map of entities and their relationships, kept current as the underlying data changes.
It runs on four components that each depend on the others:
- Ontology. A formal model that defines the types of entities the enterprise cares about (customers, accounts, transactions, counterparties), the relationships between them, and the attributes that describe them. The ontology is the shared vocabulary the graph provides. Without it, different teams query the same data using different definitions and reach different conclusions.
- Entity resolution. The process of recognizing that the same real-world entity appears under different identifiers, names, or formats across source systems, and consolidating those into a canonical representation with a stable identifier. This is the component most operationally difficult at scale if not designed with clear accuracy thresholds and ongoing monitoring.
- Ingestion and synchronization. The pipelines that bring source data into the graph and keep it current. Common patterns include batch ingestion for historical data, change data capture for near-real-time updates, and API-based federation for data best queried in place rather than copied into the graph.
- Governance layer. Access controls, audit trails, and provenance records that determine who can read or modify which parts of the graph, and that let every fact be traced back to its source and timestamp.
What makes the system enterprise is not the graph database itself. It is the continuous reconciliation of meaning, identity, and policy across changing systems at enterprise scale.
Each component's failure undermines the rest. Without the ontology, the graph stores connections without knowing what they mean. Without entity resolution, the same entity exists in multiple forms and every query inherits the inconsistency. Without governance, the graph cannot be used in regulated environments where auditability is non-negotiable.
Where are enterprise knowledge graphs used in production?
Knowledge graph practice has moved from research curiosity to enterprise procurement, and the signal sits in places vendor pitches rarely look.
Gartner has tracked knowledge graphs as a named technology across multiple Hype Cycles for years, and its 2025 Hype Cycle for Generative AI lists GraphRAG (the pattern that pairs knowledge graphs with LLMs for retrieval) as less than two years from mainstream adoption. The Knowledge Graph Conference, founded in 2019, now draws sponsorship from Bloomberg, JPMorgan, AstraZeneca, the World Bank, and most major graph vendors. The room is mostly buyers.
Named enterprise deployments include:
- LinkedIn's Economic Graph. A connected model of members, companies, jobs, skills, and schools that powers recruitment, skills inference, and labor market analysis.
- Bloomberg's Knowledge Graph. Integrates security, company, person, and event data behind the terminal.
- eBay's product knowledge graph. Drives search, recommendations, and seller tooling across a multi-billion-item catalog.
- AstraZeneca's biomedical knowledge graph. Connects clinical, genomic, and research data to accelerate drug discovery decisions.
- Major banks and government agencies. Use enterprise knowledge graphs to integrate counterparty data, regulatory filings, and transaction history for anti-money-laundering and fraud investigation.
The enterprise knowledge graph is now part of the operating stack at companies whose data has to do real work.
What should organizations evaluate before implementing an enterprise knowledge graph?
Enterprise knowledge graph projects fail more often at the organizational layer than the technical one. The following are the points where implementations most commonly break down, and where vendor claims diverge most from what production conditions actually require.
Entity resolution accuracy
Ask vendors to demonstrate entity resolution accuracy on data similar to your own. In a demo, benchmark conditions are controlled. But production data contains historical naming variations, legacy system errors, and edge cases the test set did not include. Ask how confidence scoring works: whether low-confidence matches go to human review or are auto-merged, and what monitoring exists to catch accuracy degradation over time.
A misidentified entity in a knowledge graph contaminates every path that runs through it. In a regulated environment that means incorrect risk scores, misfiled reports, or transactions linked to the wrong counterparty. These errors propagate silently until they surface in an audit or a compliance review.
Ontology ownership after go-live
Ask who owns the ontology after the implementation project closes. Not during the build, week to week afterward. Ontologies have to change as business definitions shift, new data sources arrive, and regulations update. The ontology that fails an enterprise is the one nobody owned six months after launch.
Enterprises should evaluate whether they have long-term stewardship processes for ontology, identity resolution, lineage, and governance before implementation begins. Those that have not assigned clear ownership and a change process before go-live often struggle to scale beyond their initial use case.
Semantic lift at ingestion
Most enterprise data environments encode meaning downstream. Business definitions live in ETL scripts, join logic, dashboard calculations, and analyst notebooks. When a source system changes its format, when a business definition shifts, or when a new data source arrives, those encodings have to be found and updated individually. Some get updated. Others do not. The inconsistency accumulates until it surfaces in conflicting reports, failed reconciliations, or query results that no longer reflect current definitions. The root problem is structural. Meaning is distributed across every place it was ever needed, with no single point of control.
Semantic lift is the practice of mapping raw source data to the ontology at ingestion rather than reconstructing meaning at query time. The translation effort becomes centralized rather than duplicated across downstream systems. When a field definition changes, the update can be managed at the semantic layer instead of being independently reimplemented across every dashboard, query, and transformation pipeline. When new sources arrive with different schemas, they can be mapped to the same ontology the existing data already uses, allowing historical and current data to remain queryable through a shared semantic model with less downstream rework.
Evaluate vendors on how they handle semantic lift: whether mappings are versioned and auditable, whether the ontology can evolve without breaking existing mappings, and whether new sources can be onboarded by a data steward rather than requiring engineering.
Query performance at scale
Multi-hop queries (those that cross several relationship steps to reach an answer) are where an enterprise knowledge graph proves its value. They are also where performance most commonly breaks down. Ask vendors to demonstrate query performance at the data volume and traversal depth your use case actually requires. Production data is messier and bigger than what demos run on.
The Graph Data Council (GDC, formerly LDBC) maintains the industry-standard graph database benchmarks, including the Social Network Benchmark's Business Intelligence workload, which specifically tests multi-hop traversal performance at production scale. Published LDBC results show order-of-magnitude differences between platforms on the same workload. That spread is a reminder that vendor demos rarely reflect what production conditions require.
For use cases that need responses at transaction speed (real-time fraud detection, for example) ask specifically whether the platform supports pre-computed traversals, indexing strategies, or cached aggregations. On-demand multi-hop queries across large graphs often struggle to meet sub-second latency requirements without architectural accommodations.
When is an enterprise knowledge graph not the right choice?
An enterprise knowledge graph fits where the enterprise needs to answer complex, changing questions across many connected data sources and where the relationships between entities matter as much as the entities themselves.
It is not the right fit where query patterns are stable and well-defined, where entity types are few, where source systems are clean and well-structured, or where data governance and stewardship functions do not yet exist. A knowledge graph reflects and amplifies the quality of the data it is built from. It does not substitute for governance that is not there yet.
Learn more about enterprise knowledge graphs from DataWalk
- Knowledge Graph Software | Unified Knowledge Graph Software: How DataWalk combines knowledge graph, ontology, reasoning, and AI capabilities into a single platform for enterprise data integration and analysis.
- Entity Resolution Software: How DataWalk approaches entity resolution, matching, linking, and consolidating records across source systems into unified 360-degree entity views, using no-code rules and machine learning.
- What Is an Ontology? A practical guide for enterprise data and AI teams: A closer look at what ontologies are, how they differ from data models, and why they serve as the semantic schema that gives a knowledge graph its meaning.
- Entity Resolution in Financial Crime: A Practical Guide to Uncover Hidden Risks: How entity resolution applied to a knowledge graph can surface hidden relationships in financial crime data, reduce false positives, and improve investigation accuracy.


Dr. Michael O’Donnell is a Senior Analyst covering data management strategy, with a particular interest in the gap between data and business value. He tracks the full stack (converged platforms, semantic enrichment, knowledge graphs, data products) is interested in what each gets right, where it stops short, and what that pattern keeps revealing. His measure is simple: can the person who needs the answer get it without an engineer in the middle.
ContactTable of contents
- Key Takeaways
- What is an enterprise knowledge graph?
- Why can't a standard knowledge graph do what an enterprise knowledge graph does?
- How does an enterprise knowledge graph work?
- Where are enterprise knowledge graphs used in production?
- What should organizations evaluate before implementing an enterprise knowledge graph?
- When is an enterprise knowledge graph not the right choice?
- Learn more about enterprise knowledge graphs from DataWalk
FAQ
Join the next generation of data-driven investigations:
Discover how your team can turn complexity into clarity fast.
Solutions
Product
Partners
Company
Resources
Quick Links