DataWalk Technology
DataWalk has developed hybrid graph/relational technology to enable quick data integration and fast analysis of vast amounts of complex data.
Full-Stack Analytics Platform
DataWalk is a full-stack analytics platform which is architected to seamlessly scale to handle vast amounts of data, regardless of the shape of your data and the questions you want to ask of your data.
- Ingest without extensive preparation, using either passive sinks, an ETL tool, DataWalk connectors, or the REST API. There’s no need to worry about how you will want to later use or analyze the data. High performance, full security, and no need to map extensive ontologies.
- Transform data during or after ingest, so that it takes the shape that you want. DataWalk can automatically repeat transformation and normalization steps with new data.
- Model data in a highly flexible knowledge graph, re-structuring data around understandable entities such as people, events, transactions, or anything else.
- Store data with full compression on a highly scalable, secure embedded database.
- Query data visually and ask any question of your data without limitations.
- Visualize your results.
- The DataWalk API enables you to use all of the above as part of your automated workflow.
- A User Interface for all of the above eliminates the cost and delays associated with relying on data scientists and scripting.
Integrated management tools to facilitate software deployment, upgrades, and backups, plus integrated monitoring tools.
Unique DataWalk Technology For Data Processing and Querying
As shown in Figure 1, DataWalk is a comprehensive system with various intuitive interfaces for accessing and analyzing data. The application server level takes requests from users or other systems and transforms them to a set of executions at the graph/relational database layer. DataWalk’s unique scale-out technologies are in the areas of information processing and querying at the database layer.
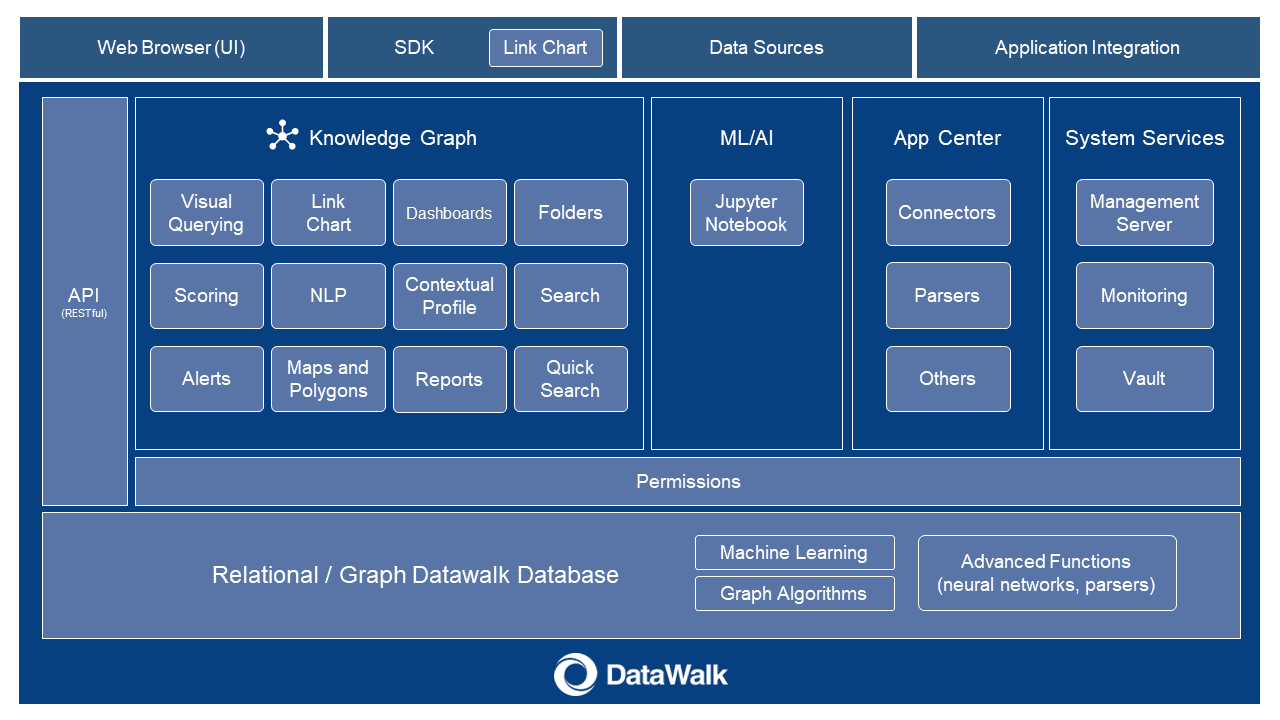
Figure 1. DataWalk system block diagram.
Hybrid Graph/Relational Database
A foundational technology of DataWalk is an innovative graph/relational database hybrid. Data and connections are persisted, and data is shared at the data level to facilitate multi-user access and collaboration. The graph structure enables: the management and analysis of complex data; the ability to derive value from connections as well as values; support for graph algorithms which can be run across vast amounts of data; and analysis of the relationships between individual objects on a link chart. Complementing this is the relational structure, which enables OLAP analytics and traditional analysis of data values. The result is a powerful capability not only to do both graph and relational/OLAP functions, but to do this against the same instance of data without requiring data movement.
Designed For Scalability
DataWalk is architected to scale in order to enable analysis of vast volumes of data. DataWalk achieves this using a horizontally scalable Massively Parallel Processing (MPP) architecture for storing and processing data, with unique technology that solves the three major challenges associated with horizontal scalability, regardless of the business model or data mapping performed: even distribution of data across multiple node, no data rebalancing needed to execute queries, and maximum information-join on stored content.
DataWalk’s unique, commercial-grade data storage solution provides flexible information management with high efficiencies required for deploying enterprise-class analytical environments. This technology delivers fast, complex, multi-dimensional analyses that are quickly completed on large, multi-billion record data sets.
Unique Knowledge Graph
The DataWalk Universe Viewer (figure 2) is an enterprise knowledge graph which provides a view of all imported data through an intuitive graphical interface showing how all the data is structured and interconnected. If desired, you can re-organize your data around understandable business objects such as people, transactions, events, or anything else. This abstraction layer enables you to operate at the level of data sets, makes it practical to integrate and analyze vast amounts of data, and enables you to find matching patterns.
The DataWalk knowledge graph manages data in a property graph model to enable data compression benefits, while also incorporating certain elements such as objects and links from triple store concepts.
Modeling And Querying Via A Knowledge Graph
The Universe Viewer is the system interface for both modeling and visual no-code querying, and allows precise identification of complex relationships between data, as well as rapid and immediate filtering of both directly and indirectly connected data sets. The Universe Viewer is easily configured for each deployment, without a fixed ontology. Combining business modeling methods with data discovery and data blending creates simple, reproducible structures and analyses. Thus, the integration process is often several hundred times faster than traditional systems. Integrating different data types and structures, from many sources, into one cohesive picture reflects a natural, human perception of information and makes DataWalk an easy-to-use system for performing complex analytics.
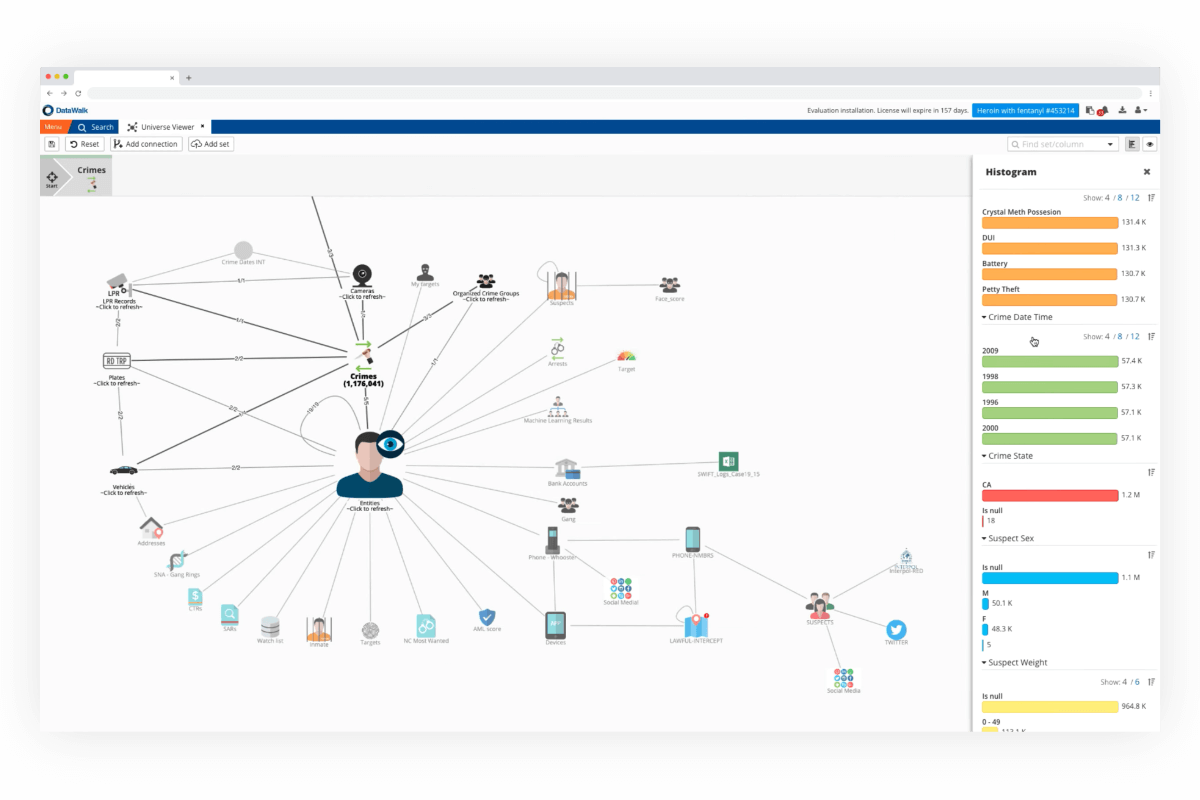
Figure 2. The DataWalk Universe Viewer.
DataWalk Flexible Data Representation
DataWalk utilizes a logical data structure that is presented on the Universe Viewer and is easily modified on the fly. There is no need to make changes to the physical model or disturb system operation to change this structure. The DataWalk structure is highly standardized, with data evenly distributed across many compute nodes to rapidly obtain answers. With DataWalk the cost of changing the logical structure is so low (and easy) that you can experiment with the logical model and freely modify it in real time. For example, you can easily create new connections, edit existing ones, or add new sources and object descriptions.
Optimized For Complex Querying
The Universe Viewer allows you to directly perform ad-hoc, no-code complex queries via an intuitive visual interface, such that neither technical expertise or programming skills are required. Queries are created in an iterative manner, and visualized in “breadcrumbs” such that you can clearly understand each step of a complex query and be assured that results will be reliable. Patented DataWalk technology ensures that complex queries complete, and will complete quickly. As shown in Figure 3 below, DataWalk has published benchmark results showing that unlike traditional relational database systems, which fail to generate a result after a relatively small number of joins, DataWalk maintains linear response time through the equivalent of 600 joins.
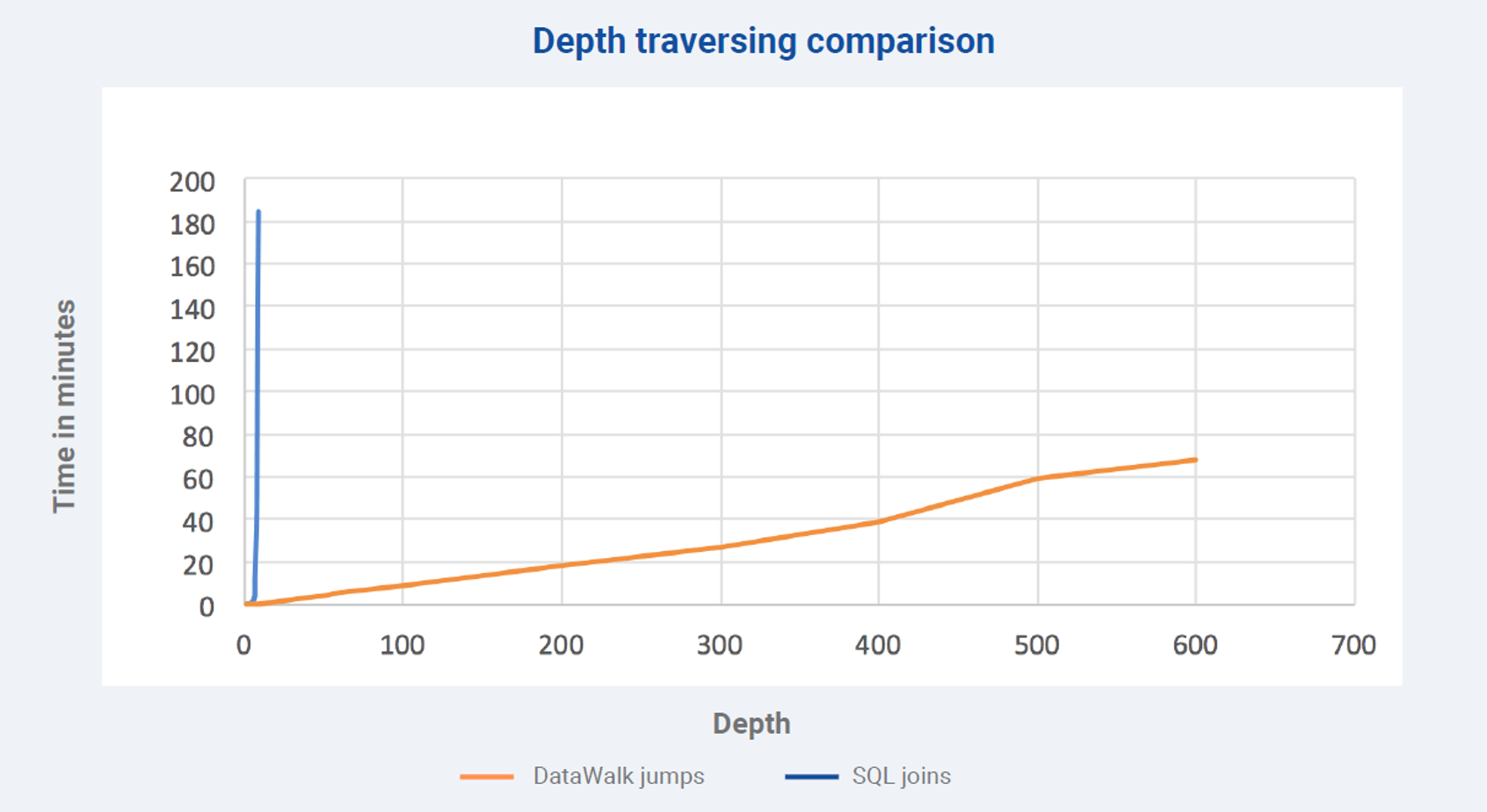
Figure 3. DataWalk maintains linear performance through 600 joins.
Fast Execution of Graph Algorithms
DataWalk’s graph-oriented technology is enhanced with ultrafast state usage, which enables exceptional performance for graph algorithms. Benchmark results have validated DataWalk’s superior performance relative to the fastest graph databases.
The DataWalk App Center
The DataWalk App Center enables programs or subroutines to run inside the DataWalk environment, although they are not part of the DataWalk code base. Apps can utilize DataWalk data and analyses, but run in a separate execution space such that an App cannot impact the reliability of the core DataWalk application. Apps can be generated by DataWalk as well as by certified partners and customers, for functions including integrations, features, machine learning models, or additional full-scale applications. The App Center also enables open-source libraries to be integrated into DataWalk, thus dramatically expanding the potential scope of system functionality. The App Center includes a graphical user interface, and Apps can also be initiated via the DataWalk API (loosely analogous to AWS Lambda).
DataWalk API – Communication
The DataWalk system is built in Java. Internally each component of the application has its own service (REST), and external access is similarly supported using APIs. Data and analyses done in DataWalk are easily made available to other programs. The connection to enterprise data stores is easily accommodated with DataWalk technology. To retrieve information from/to platforms such as Oracle, DB2, Hadoop, or other commercial systems, you can take advantage of RESTful access.
DataWalk Link Generator
The DataWalk Link Generator permits complicated analyses to be efficiently executed, based on advanced connection rules. Instead of fixed tables and pre-programmed, pre-designed analytical flows, DataWalk supports flexible, persisted data connections in a logical layer. When something is changed, the entire analytic process updates without the need for programming or interrupting system operation.
A link calculates and stores information on relationships between objects. Links can be generated based on simple rules (e.g., Field A = Field B) or with more advanced business rules to connect data, even in the absence of a primary key – foreign key relation. Links are pre-calculated and then aggregated on the fly to generate fast and accurate results. Note that while links typically are automatically calculated based on dependencies and rules – including highly advanced rules with fuzzy logic - DataWalk also enables you to import data with connections already defined.
DataWalk Data Ingestion
DataWalk uses a very flexible, adaptable, and generic method for importing content. To retrieve information from a relational database you can utilize JDBC. There are a number of available connectors to various data services and commercial solutions. You also can configure custom connectors based on JSON or XML based REST interfaces. Any data ingestion triggers a model recalculation (dependency refresh) process to keep data consistent. External systems can register ingestion events in DataWalk, after which DataWalk will reach into the registered source when appropriate. DataWalk’s various performance optimizations enable rapid ingest of large volumes of data.
DataWalk User Permissions & Access Control
A major challenge with analysis of sensitive data is guaranteeing that data and the results of system processing are consistent with user privileges. DataWalk explicitly addresses this challenge with three levels of privileges that support granular permissions while maintaining exceptional performance: access to sets of objects per user, access to an attribute of an object per user, and access to an object using access filters per user.
The system administrator defines access filters, per dataset, for a given user or group of users. The filters are applied transparently each time the system is queried by the user. The added value of filters is supported by the following features. First, the access rights are not demanding; they are processed by the system while performing a query - not after the query has been processed - which increases efficiency. Second, the access rights are manageable and do not significantly affect system efficiency.
DataWalk Search:
Optimized For Vast Amounts Of Data
The DataWalk search facility is optimized to meet the challenge of providing useful results when searching vast amounts of data. DataWalk supports a targeted search facility that enables you to configure the specific fields you want to search – across any of your desired data sets - for any type of entity, delivering results that are far more precise.
You Might Like
