
What Is a Knowledge Graph?
Structure, Semantics, and the Difference That Matters
Key Takeaways
- Data + Ontology = Knowledge Graph. A graph stores connections. A knowledge graph stores connections that mean something, defined by an ontology that tells the machine what each entity and relationship is.
- Knowledge graphs run Google search, LinkedIn's Economic Graph, Facebook's Social Graph, and Wikidata. The same architecture is now reaching the enterprise.
- The difference between a graph database and a knowledge graph is meaning, not structure. A graph database stores and traverses connections fast. A knowledge graph adds the semantic layer that lets the data answer questions, not just be retrieved.
- Knowledge graphs are now the grounding layer for LLMs. Gartner's 2025 Hype Cycle for Generative AI places GraphRAG, the pattern that pairs knowledge graphs with LLMs to reduce hallucination, less than two years from mainstream adoption.
- Three challenges show up in every enterprise implementation: resolving the same entity across systems, designing an ontology that can evolve, and keeping the graph accurate as data changes. None are novel. All have established engineering responses.
What is a knowledge graph?
A knowledge graph is a data model that represents real-world entities (people, organizations, transactions, events) as nodes connected by typed relationships, with an ontology that defines what those entities and relationships mean.
In other words: a graph database stores (A) → (B). A knowledge graph stores (JPMorgan Chase) → "subsidiary_of" → (JPMorgan Chase and Co.) and knows what "subsidiary_of" implies.
Google introduced the term in 2012 to describe a shift in how its search engine handled queries. Rather than matching keywords (the old approach Google called "strings"), the system began identifying entities, specific disambiguated things, and returning structured facts about them. That same design principle, treating data as a network of defined entities rather than a bag of strings, is what enterprise knowledge graphs apply to organizational data.
How Ally Built a Modern Fraud Intelligence Platform
Learn how Ally applied graph analytics and contextual investigation tools to uncover complex fraud networks and strengthen fraud prevention.
Read Case Study
Why can't a graph database do what a knowledge graph does?
| Relational database | Graph database | Knowledge graph | Enterprise knowledge graph | |
|---|---|---|---|---|
| What it is | Stores structured records in tables linked by keys | Stores nodes and edges optimized for traversing relationships | A graph with a semantic model that defines entities, relationships, and meaning | A knowledge graph extended with governance, entity resolution, provenance, and operational management across enterprise systems |
| Primary purpose | Transaction processing, reporting, structured analysis | Fast traversal of connected data | Represent real-world entities and relationships with semantic meaning | Maintain consistent, governed, explainable context across fragmented organizational data |
| Relationship handling | Relationships reconstructed through joins | Relationships are first-class structures | Relationships are typed and semantically defined | Relationships are semantically defined, governed, reconciled, and maintained across systems over time |
| Semantic layer | No | Optional / application-defined | Yes: ontology and semantic model | Yes: ontology plus operational governance and stewardship |
| Can infer relationships? | No | Limited | Yes, through ontology and reasoning rules | Yes, with governance, provenance, and enterprise policy controls |
| Best suited for | Financial systems, reporting, transactional workloads | Network analysis, recommendations, pathfinding | Semantic search, AI grounding, entity-centric intelligence | Regulated environments, investigations, enterprise AI, multi-system operational intelligence |
| Main challenge at scale | Join complexity and schema rigidity | Semantic inconsistency across applications | Ontology design and entity resolution | Long-term governance, stewardship, synchronization, and semantic consistency across changing systems |
Not every knowledge graph is enterprise-grade. Enterprise knowledge graphs introduce operational requirements around governance, identity reconciliation, provenance, stewardship, and long-term semantic consistency across systems.
Interesting Anecdotes
- At launch in May 2012, Google's Knowledge Graph contained over 500 million objects and more than 3.5 billion facts, drawing from Freebase, Wikipedia, and Wikidata.
- By May 2020, Google's Knowledge Graph had grown to 500 billion facts across 5 billion entities, illustrating the scale achievable when knowledge graph infrastructure is treated as core search infrastructure.
- The Alan Turing Institute defines three properties that distinguish knowledge graphs from graph databases: they are graph-structured, semantically encoded via an ontology, and alive, meaning they evolve as new data arrives.
- Gartner's 2025 Hype Cycle for Generative AI classifies GraphRAG (the pattern that combines knowledge graphs with large language models for retrieval) as less than two years from mainstream adoption.
- ACM Queue research across industry-scale knowledge graph implementations identifies entity disambiguation as the top persistent challenge at Google, Microsoft, and LinkedIn.
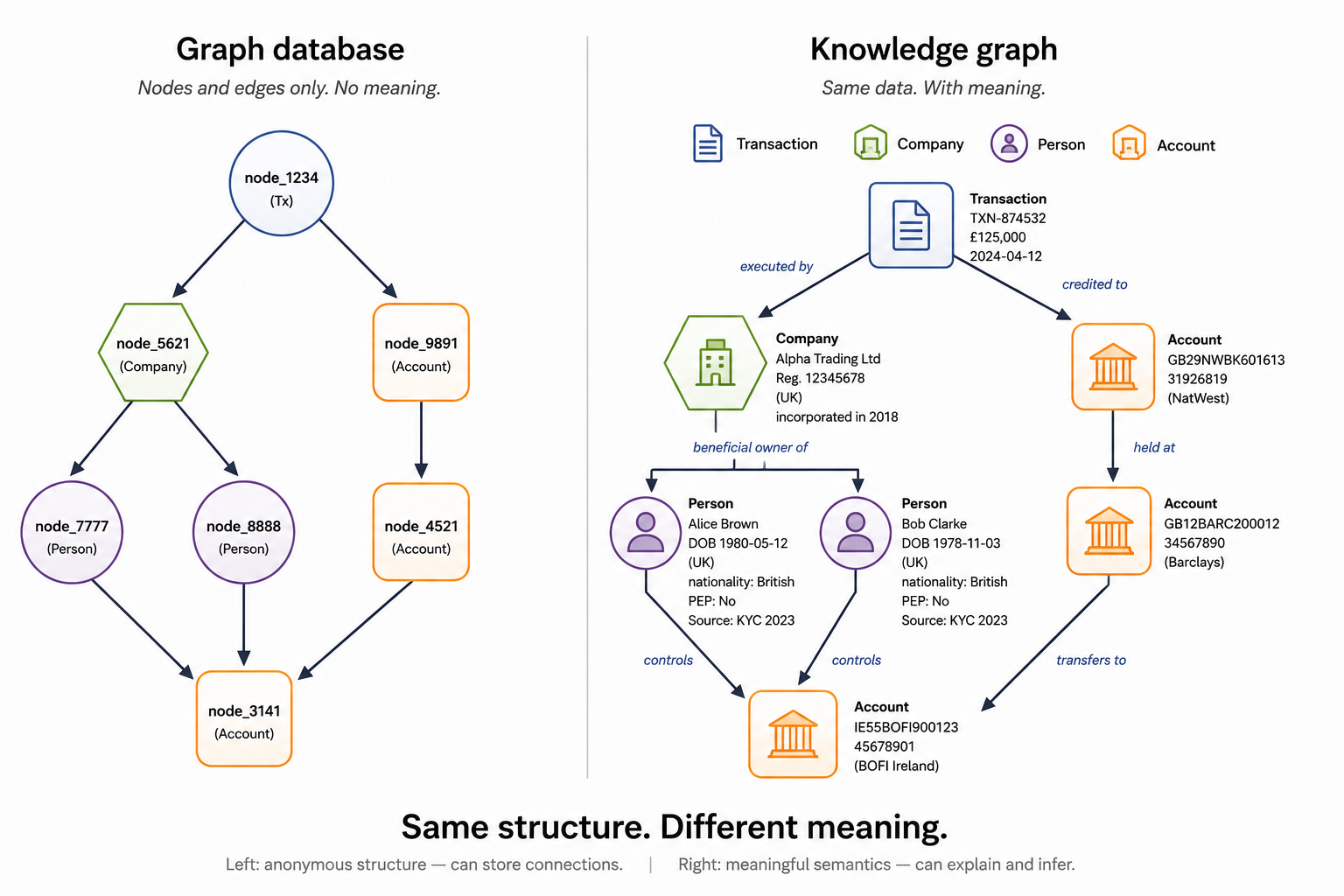
How does a knowledge graph work?
Three components: entities, relationships, and an ontology.
Think of a city map. Intersections are nodes. Roads between them are edges. But a map of dots and lines tells you only which points connect, not whether a road is a motorway or a cycle path, whether it is one-way, whether it crosses a restricted zone. The ontology is the layer that adds that meaning. Without it, you have topology. With it, you have a navigable model of the real world.
- Entities (nodes). Real-world objects: a person, a company, a transaction, an event. Each entity has a unique identifier and a type ("person", "company", "transaction") drawn from the ontology.
- Relationships (edges). Typed, directional connections between entities. Not just a link, but a labelled assertion: employed_by, regulated_by, subsidiary_of. The type is defined by the ontology.
- Ontology. The formal model that defines what entity types exist, what relationship types are valid between them, and what rules govern inference. It is the schema layer that makes the graph machine-interpretable rather than merely machine-stored.
The power comes from following chains. A knowledge graph can move from a transaction to the company involved, to that company's beneficial owners, to those owners' related accounts at other institutions, answering questions that require traversing more than one relationship and that no single relational query would resolve.
Where are knowledge graphs used in production?
Knowledge graphs already run the biggest production systems on the internet. Most readers use them every day.
- Google Knowledge Graph. At launch in May 2012, it contained over 500 million objects and more than 3.5 billion facts, drawing from Freebase, Wikipedia, and Wikidata. By May 2020 it had grown to 500 billion facts across 5 billion entities. It is the structured backbone behind the right-hand answer panels and a major signal in modern search ranking.
- LinkedIn's Economic Graph. LinkedIn models its members, companies, jobs, skills, and schools as a connected graph that powers job matching, skills inference, and recruiter search at planetary scale.
- Wikidata. A community-maintained knowledge graph that now serves as a citation source for Google, LLMs, and academic systems.
- GraphRAG and enterprise AI grounding. Gartner's 2025 Hype Cycle for Generative AI classifies GraphRAG, the pattern that combines knowledge graphs with LLMs for retrieval, as less than two years from mainstream adoption with a Moderate benefit rating. This is the wave bringing knowledge graphs into mid-market enterprises that had no graph practice in 2024.
The Alan Turing Institute defines three properties that distinguish a knowledge graph from a graph database: it is graph-structured, semantically encoded via an ontology, and alive, meaning it evolves as new data arrives. The "alive" property is the one most enterprise implementations underestimate.
What kinds of knowledge graphs are there? RDF vs property graphs
There are two major flavors of knowledge graph, with different histories and different ecosystems.
- RDF graphs. The Resource Description Framework is a W3C standard that grew out of the Semantic Web. Data is stored as triples: <subject> <predicate> <object>. Each element gets a globally unique URI, so the same entity can be referenced across organizations and systems without renaming. Queries are written in SPARQL, and ontologies are usually written in OWL, the W3C ontology language that sits on top of RDF and supports formal reasoning (class hierarchies, restrictions, inferred relationships). RDF dominates life sciences, government open-data programs, library and museum catalogues, and Wikidata.
- Property graphs. The model popularized by Neo4j. Nodes and relationships are first-class objects, each carrying arbitrary key-value properties. Queries are written in Cypher, openCypher, or Gremlin. Property graphs dominate developer-driven use cases: recommendation engines, fraud detection, network analysis, application back-ends.
The two models can represent the same information. The real difference is lineage. RDF is older and built for cross-organization interoperability. Property graphs are newer and easier to start building in.
RDF and property graphs are the dominant flavors but the field is wider than that.
- Hypergraphs let a single edge connect more than two nodes at once, handling n-ary relations that don't fit the subject-verb-object frame ("Alice gave Bob a book on Tuesday" is one fact, not three).
- Metagraphs allow edges to connect other edges, or whole sub-graphs, useful when the structure itself needs to be queryable as data.
- Context graphs, a 2026 framing, name graphs designed specifically to feed LLM context windows. The label is newer than the technique.
Most production work still happens in RDF or property graphs. The shape of the field is widening as the use cases get more demanding.
Why are Knowledge Graphs rising in popularity?
2026 is the year of context.
Two things determine whether an AI system is useful: the model and the context that goes into it. The LLM model is a commodity. The context is not.
The industry term for the discipline is context engineering, which has quietly displaced prompt engineering as the place production AI work actually happens. Production AI engineers now spend their time deciding what facts and provenance arrive in the LLM model's context window on every call.
A knowledge graph is built for that job. It returns typed facts the model can traverse and a human can audit. A document dump or a vector retrieval gives the model approximations; the graph gives it ground truth, traceable back to source.
This is why the Turing Institute's "alive" property matters. A static context store decays the moment your business changes. A knowledge graph keeps reconciling new data into the existing structure, which is the only kind of context substrate that keeps pace with the systems it grounds.
What is the difference between Knowledge Graphs and GraphRAGs?
A knowledge graph is the data. GraphRAG is what you do with it to ground an LLM.
- A knowledge graph is the structured artefact: entities, typed relationships, and an ontology that defines what everything means. It lives in your data infrastructure whether or not an LLM ever touches it.
- GraphRAG is a retrieval pattern. When an LLM needs context to answer a question, GraphRAG queries the knowledge graph instead of doing vector search over a document store. The model gets back a typed sub-graph of entities and relationships, rather than a bag of nearest-neighbor text chunks. The output is more accurate and capable of multi-hop reasoning that vector retrieval can't deliver.
One knowledge graph can power many GraphRAG implementations: a customer-service agent, a fraud investigation copilot, an internal search assistant. They share the underlying graph. They differ in what they retrieve and how they prompt the model.
GraphRAG without a knowledge graph underneath collapses into ordinary RAG with a fancier name. The graph is what does the context work.
Learn more about knowledge graphs from DataWalk
- 1. Ontologies and Knowledge Graphs: How ontology modeling works in practice, covering entity types, attributes, and connections so analysts can query data without coding.
- 2. Grounding Large Language Models with Knowledge Graphs: How DataWalk implements GraphRAG, using a structured knowledge graph to ground LLM responses in verified, queryable enterprise data.
- 3. Introduction to Knowledge Graphs (Whitepaper): A deeper treatment of knowledge graph structure, use cases, and enterprise implementation considerations.
- 4. Entity Resolution Software: How DataWalk resolves entities at scale across heterogeneous sources, the production answer to the disambiguation challenge described above.
- 5. Knowledge Graph Software | Unified Knowledge Graph Software: DataWalk's unified knowledge graph platform, combining graph, ontology, inference, and AI in a single data layer.


Dr. Michael O’Donnell is a Senior Analyst covering data management strategy, with a particular interest in the gap between data and business value. He tracks the full stack (converged platforms, semantic enrichment, knowledge graphs, data products) is interested in what each gets right, where it stops short, and what that pattern keeps revealing. His measure is simple: can the person who needs the answer get it without an engineer in the middle.
ContactTable of contents
- What is a knowledge graph?
- Why can't a graph database do what a knowledge graph does?
- How does a knowledge graph work?
- Where are knowledge graphs used in production?
- What kinds of knowledge graphs are there? RDF vs property graphs
- Why are Knowledge Graphs rising in popularity?
- What is the difference between Knowledge Graphs and GraphRAGs?
- Learn more about knowledge graphs from DataWalk
FAQ
Join the next generation of data-driven investigations:
Discover how your team can turn complexity into clarity fast.
Solutions
Product
Partners
Company
Resources
Quick Links