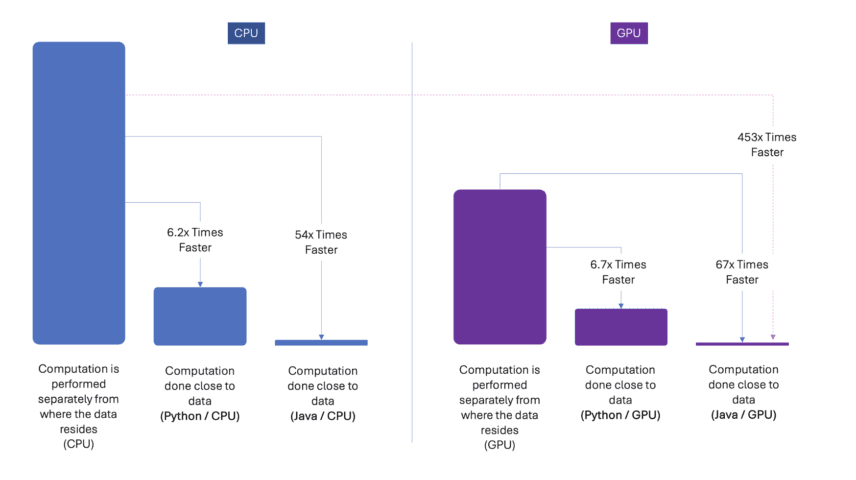
Figure 2: Comparison of computational performance in DataWalk. The figure illustrates three scenarios for both CPU (left) and GPU (right): baseline performance with computation performed in a location separate from the data and optimized performance with computation close to the data using Python and Java. Key performance improvements: Python achieves a 6.2x speedup on CPU and 6.7x on GPU, while Java delivers the highest speedups of 54x on CPU and 67x on GPU. The results highlight the significant benefits of performing computation near the data, especially when using Java and GPU-based approaches.

Entity Extraction on Steroids
Transforming Entity Extraction with GLiNER and DataWalk
Many organizations face challenges in efficiently resolving entities across vast and disparate datasets. A data officer at a multinational corporation posed a seemingly simple question: "How can we find all the personally identifiable information (PII) across millions of documents?" This question wasn’t just about identifying names or phone numbers—modern AI tools can handle that. The true challenge was extracting these entities from millions of records, including scanned PDFs, unstructured notes, and multilingual datasets, while maintaining critical context.
Context matters. For example, is “John Smith” an employee in an HR file or a client in a legal contract? Traditional methods often treat entities as isolated fragments, leading to incomplete or misleading insights. Further complicating this data challenge, sensitive data had to remain on-premises, ensuring PII security and compliance without exposing it to third-party providers.
Enter GLiNER, an advanced neural network, and DataWalk to provide a groundbreaking solution together. We deployed GLiNER through our App Development Framework to achieve this, initially performing computations outside the DataWalk platform. We then optimized the process by moving computation to the layer where the data resides, eliminating inefficiencies. The optimization included running tests across different configurations, leveraging GPU and CPU processing, and utilizing Java and Python for execution. This approach ensures unmatched scalability and performance and streamlines workflows by making extracted entities immediately available for analysis within DataWalk’s integrated analytics platform, maintaining context and eliminating unnecessary data transfers.
What is GLiNER?
“GLiNER employs a global linearization strategy, treating the entire input sentence as a single linear sequence rather than dividing it into tokens or individual words. This approach allows the model to capture a more comprehensive contextual understanding of the sentence, resulting in more accurate entity recognition.”
– Ubiai
You can find more information about GLiNER at https://arxiv.org/abs/2311.08526 and the repository here: https://github.com/urchade/GLiNER.
While the results in this paper focus on GLiNER, any model can be incorporated into DataWalk’s App Development Framework.
The Traditional Approach: Computing Away from the Data
Conventional data processing often involves a cumbersome cycle. First, data is extracted from its storage container and moved to a separate computing environment. After processing, it's returned to storage, but that's not the end. This processed data must be aligned and integrated with other information sets to be truly useful. This multi-step approach with data movement consumes time and introduces potential inconsistencies and delays in data availability. This cycle becomes even more complex and time-consuming for systems with multiple data processing capabilities. This approach introduces latency due to data transfer and can become a bottleneck, especially with large datasets.
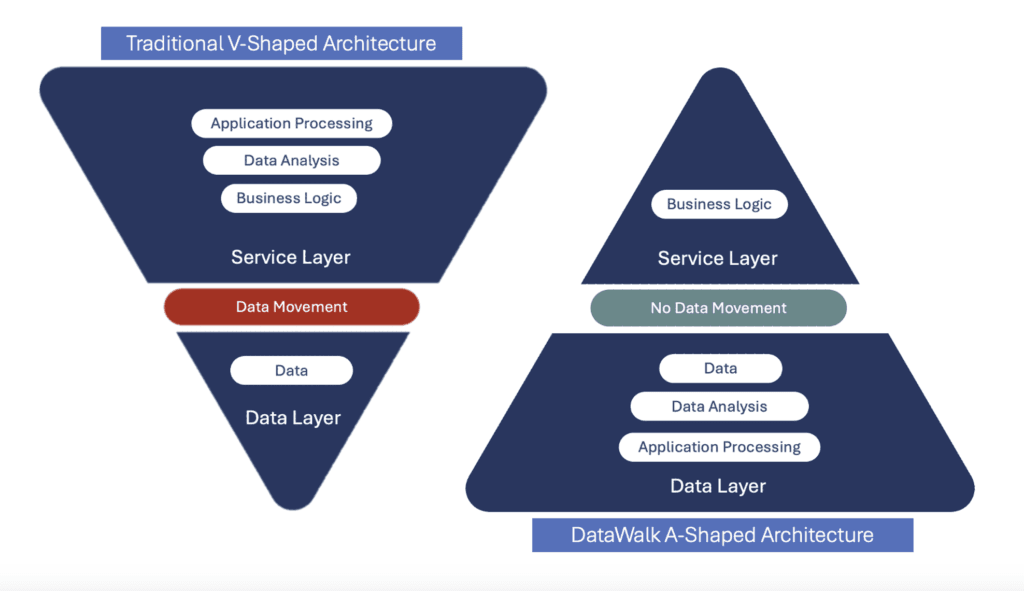
Figure 1: The illustration of 2 types of architectures: Traditional V-shaped architecture, where the computation layer (e.g., entity extraction) is separated from the data layer, and the DataWalk A-shaped model, where computation is executed where data resides. Learn more about V-shaped and A-shaped architectures here: https://datawalk.com/enterprise-data-architecture/
Even when using GLiNER, these traditional methods remain inefficient. While GLiNER is a powerful tool for entity extraction, it is not a panacea. In a conventional workflow, entity extraction tasks are continually slowed down by the back-and-forth movement of data between environments, undermining the speed and efficiency required for real-time or large-scale applications.
The DataWalk Approach: Computing Where the Data Resides
The ideal solution for processing large data volumes would be to compute data where it resides. This approach minimizes latency, reduces complexity, and ensures scalability by eliminating the need to transfer data between storage and external systems for tasks like Entity Extraction. Performing computations directly within the storage environment streamlines workflows and avoids the inefficiencies of reintegrating processed data into broader datasets.
DataWalk’s architecture exemplifies this unique approach. Every computation—whether triggered by an external system or through its intuitive UI—is executed directly where the data is stored. This architecture eliminates the need for data to travel outside its storage for processing, significantly reducing delays, enhancing scalability, and eliminating the additional step of reintegrating processed data for analysis.
By integrating GLiNER into this in-place computation framework close to data, Entity Extraction tasks are completed faster and with immediate incorporation of results. Insights are ready for analysis without the overhead of moving data across multiple layers. This architecture leverages DataWalk’s existing capabilities, resulting in faster, more efficient processing for large-scale, data-driven applications.
DataWalk Platform: Instant Accessibility for Comprehensive Analysis
One of DataWalk's standout features as a platform is the immediate availability of computations across the entire system. When GLiNER performs data and context extractions, these results are instantly accessible to all DataWalk users or results consumers. This seamless integration ensures that insights derived from GLiNER are readily available through various channels:
- APIs: Developers can directly integrate DataWalk GLiNER into their applications by calling into GLiNER via a DataWalk-exposed API, enabling the consumption
- Universe Viewer: This knowledge graph representation allows non-technical users to visually explore GLiNER-derived insights within the context of the organization's data domain, supporting tasks such as entity resolution and relationship analysis.
- Link Charts: Users can access GLiNER output through link charts for more detailed, relationship-focused analysis and visualization
- Analytical Tools: Analysts using DataWalk's suite of tools can immediately incorporate GLiNER computations into their workflows.
This immediate accessibility enhances the synergy between DataWalk and GLiNER, elevating their outputs into actionable insights that empower decision-making and drive comprehensive analysis across the entire organization. Ensuring that every computation is immediately available throughout the DataWalk platform enables users to leverage GLiNER's outputs in real time, providing a dynamic and responsive environment for data-driven insights. This integration underscores DataWalk's commitment to delivering comprehensive, scalable solutions that meet the evolving needs of modern organizations.

Figure 2: Comparison of computational performance in DataWalk. The figure illustrates three scenarios for both CPU (left) and GPU (right): baseline performance with computation performed in a location separate from the data and optimized performance with computation close to the data using Python and Java. Key performance improvements: Python achieves a 6.2x speedup on CPU and 6.7x on GPU, while Java delivers the highest speedups of 54x on CPU and 67x on GPU. The results highlight the significant benefits of performing computation near the data, especially when using Java and GPU-based approaches.
Language Matters: Transition from Python to Java
The programming language you use can have a significant impact on performance. In our case, we initially implemented GLiNER using Python due to its ease of use and rich ecosystem of data science libraries. However, due to its interpreted nature, Python can be slower for compute-intensive tasks. By transitioning to Java, a language known for its performance and efficiency, we were able to unlock additional speed improvements. The switch to Java optimized GLiNER's processing capabilities, making it more responsive and appropriate for handling large-scale data within the DataWalk ecosystem.
Leveraging GPU Acceleration: Supercharging GLiNER's Performance
GPUs (Graphics Processing Units) are well-suited for the parallel processing demands of neural networks like GLiNER. As shown in Figure 2 above, by offloading compute-intensive tasks from the CPU to the GPU, we significantly enhanced GLiNER's processing speed. This acceleration is especially beneficial for large-scale entity extraction tasks, where the volume of data and complexity of computations can be vast. With GPU acceleration, GLiNER can process more data in less time, delivering insights faster and more efficiently than ever before.
Expanding Neural Network Capabilities in DataWalk
GLiNER represents just one of the many advanced neural network subsystems within the DataWalk platform. We've integrated various neural networks and advanced techniques to tackle diverse tasks, from address processing to phone analysis and embedding creation. These neural networks operate seamlessly within DataWalk, delivering targeted solutions that enhance data processing and analysis capabilities.
Conclusion: Enhancing GLiNER's Performance with DataWalk
The integration of GLiNER into DataWalk represents a transformative step in entity extraction and analysis. By enabling the extraction of entities from 7.5 million report narratives in just 3 hours, with immediate access to results in the DataWalk Knowledge Graph, this solution dramatically reduces delays from months to hours. This speed and efficiency allow teams to iterate quickly, correct errors, and maintain the highest data security and accuracy levels.
DataWalk’s innovative architecture—bringing computation close to the data—has been pivotal in achieving these results. Transferring GLiNER from external computation to direct processing within the DataWalk database maximized performance improvements. Further enhancements, such as shifting from Python to Java and utilizing GPU acceleration, enabled GLiNER to handle large-scale entity extraction while ensuring scalability and reliability efficiently.
More than just a fast and secure solution, DataWalk’s architecture exemplifies versatility. From transforming unstructured text into actionable intelligence with GLiNER to applying specialized neural networks for tasks like phone and address analysis, the platform equips organizations with the tools to address complex challenges. This capability empowers users to unlock the full potential of their data and make informed, impactful decisions.
By combining cutting-edge technology, speed, and adaptability, DataWalk ensures that organizations can confidently navigate their analytical needs and achieve meaningful, efficient results.
Solutions
Product
Partners
Company
Resources
Quick Links