
Blog article
by Monika Oskard, CFE
Graph enthusiast and fraud expert with many years of experience in consulting anti-fraud strategy and developing fraud detection & prevention solutions with use of data and analytics (ML, SNA & expert rules).
Relational Model Database
vs.
The DataWalk Knowledge Graph
In the era of big data and analytics, knowledge graphs and relational databases represent two approaches to data organization, each with unique strengths and applications. While both models aim to structure data interconnectedly, they diverge significantly in their underlying philosophies and practical uses. This article delves into the nuances between these two models, showing how knowledge graph data modeling differs from relational database modeling and emphasizing the advantages of this approach.
The key differences in data modeling
This paragraph reveals three pivotal aspects distinguishing knowledge graphs from relational database graphs: Data Structure, Data Joining, and Ontology.
Data Structure
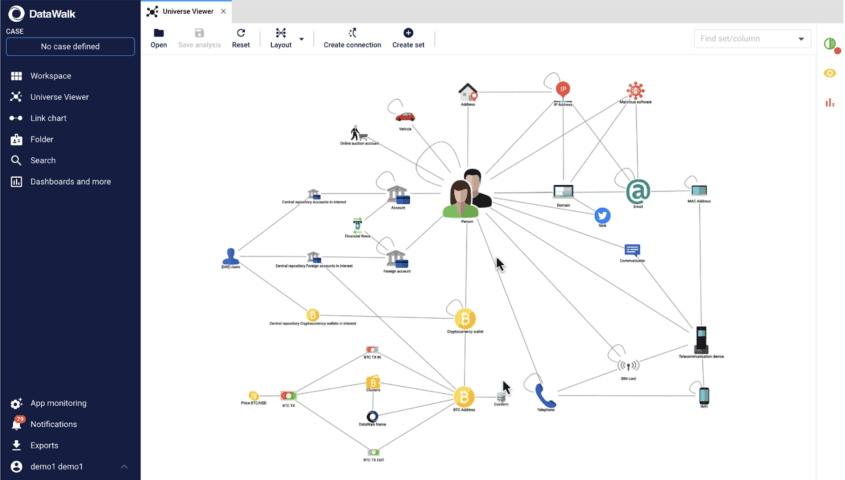
First, knowledge graphs excel in structuring data as interconnected entities and relationships, closely mirroring the complexity of real-world interactions, a stark contrast to the table-centric organization of relational databases. Knowledge graphs focus on encapsulating generic knowledge, optimizing for a comprehensive understanding and the possibility of answering every question in the field. The model is intuitive and generic, so organizations can easily extend it when new aspects and data appear. While relational databases are rather performance-centric, they concentrate on creating a structure optimal for query performance that is usually not intuitive from the end-user perspective. This difference not only affects the representation of data but also its accessibility.
Interconnections representation
DataWalk's knowledge graph architecture takes a fundamentally different approach to data connections compared to traditional methods. DataWalk excels at representing complex, real-world relationships through direct links, allowing for nuanced and flexible relationship conditions using advanced algorithms.
In conventional databases, exact matching is typically achieved through primary-foreign key relationships, which are inherently strict. While other types of relations can be encapsulated in SQL queries, this approach quickly becomes unwieldy and difficult to maintain as complexity increases.
In contrast, links in a the knowledge graph approach are treated as first-class citizens in analytics. They're not just passive connectors, but active, queryable entities in their own right. Analysts can directly query, analyze, and derive insights from the links themselves, opening up new dimensions of data exploration and pattern discovery. This elevation of links to primary analytical objects significantly enhances the depth and breadth of possible analyses, allowing for more sophisticated and nuanced insights into interconnected data. DataWalk allows a single link to connect objects based on multiple attributes, such as name and surname (processed through phonetic algorithms like Soundex) and birth date. This capability transcends the limitations of conventional database relationships, offering greater depth and adaptability in data associations.
Furthermore, in our graph-based architecture, relationships aren't just simple connections - they can have their own attributes and even interconnect with other relationships. Notably, with DataWalk's specialized structures, you can create links to links. This unique feature allows for the representation of meta-relationships, enabling the modeling of complex, multi-level interactions that are challenging or impossible to represent in traditional systems.
This multi-dimensional approach enables a more comprehensive and realistic representation of complex data ecosystems, capturing nuances that would be lost in simpler models.
Ontology
The incorporation of ontology in knowledge graphs is a fundamental difference. Knowledge graphs can infer insights not explicitly stated in the data by utilizing an ontology—a structured framework that defines relationships of entities and their properties. Such an approach enables organizations to store complex organizational knowledge in an accessible format, promoting seamless knowledge transfer across departments and to new team members. This intuitive, cognitive alignment contrasts with the relational database model, often demanding a more technical understanding to navigate complex relationships.
Advantages of knowledge graph over relational databases
Building upon the foundational differences, exploring the advantages of knowledge graphs over relational databases is crucial. This underscores why knowledge graphs, particularly those implemented by DataWalk, are increasingly preferred for complex and changeable data landscapes.
Complex Queries and Data Traversal
DataWalk's Knowledge Graph excels at enabling the easy execution of complex queries. This sharply contrasts with relational databases, where similar queries often require extensive joins or even changes to the underlying model, becoming increasingly cumbersome and sometimes computationally impossible.
In traditional SQL-based systems, complex queries not only demand intricate joins but also become difficult to debug and maintain. Constructing these queries requires a detailed understanding of both the question at hand and the specific database structures needed to answer it. This complexity often leads to opaque, error-prone queries that are challenging even for experienced database administrators.
DataWalk transforms this process. Instead of wrestling with complex SQL, users can traverse the data intuitively, simultaneously exploring potential answers and refining their questions. This approach turns data analysis into a journey of discovery, where the path to insight is as valuable as the destination. It allows for a more flexible, adaptive approach to data exploration, enabling users to uncover relationships and patterns that might not have been apparent at first.
Scalability
DataWalk's knowledge graph technology offers superior scalability, not just in data storage but in query execution and processing. DataWalk efficiently handles large data volumes through a horizontal scaling architecture.
What distinguishes DataWalk is its ability to automatically optimize and distribute any query or request across multiple computation nodes. Whether a user interacts through the User Interface or an external system makes API calls, DataWalk executes these operations in the most efficient manner possible.
The system intelligently spreads the computational load across available cluster nodes without requiring additional tuning for specific queries. This automatic load balancing and optimization ensures robust performance as data volumes grow and query complexity increases.
This approach eliminates the need for manual query optimization or system reconfiguration. It allows organizations to scale their data analysis capabilities seamlessly, handling everything from simple lookups to complex analytical processes with consistent efficiency.
DataWalk's scalability is dynamic and intelligent, providing a future-proof solution that grows with your data and analytical needs while maintaining optimal performance and resource utilization.
Flexibility in Data Model Extension
Knowledge graphs provide exceptional flexibility when it comes to extending the data model, allowing for seamless integration of new information. This adaptability is particularly beneficial in dynamic data environments where changes are frequent and processes are continually evolving. In contrast, relational databases often require significant restructuring and schema modifications to accommodate new data types or relationships, making them less agile in adapting to changes. The inherent flexibility of knowledge graphs supports the incorporation of diverse data sources and complex relationships without the need for predefined schemas. This capability ensures that organizations can quickly respond to new insights and requirements, maintaining the relevance and accuracy of their data models.
Inferencing and Reasoning
Knowledge graphs are designed to naturally support logical inferencing and reasoning, making it easier to derive insights and deductions from the data. This capability allows for straightforward identification of complex relationships, such as familial connections, which would otherwise require intricate queries and significant computational resources in traditional relational databases. The semantic nature of knowledge graphs enables them to understand and process the meaning behind data, facilitating more intuitive and efficient reasoning processes. In contrast, relational databases often lack this inherent ability, necessitating additional layers of logic and processing to achieve similar outcomes. As a result, knowledge graphs offer a more efficient and effective approach to uncovering hidden patterns and relationships within data.
Graph Algorithms Application
Graph algorithms, inherently recursive in nature, are particularly well-suited for knowledge graph data structures. This recursive quality allows for deep, multi-level traversals that SQL's expressiveness fundamentally lacks. In traditional relational databases, achieving similar functionality often requires complex stored procedures, which are tightly coupled to specific data structures and lack generality.
When applied to knowledge graph data structures like DataWalk, these algorithms enable swift identification of patterns and clusters among data objects, which is pivotal for tasks like fraud detection. They enhance investigative efficiency by reducing dependence on manual detection techniques. The recursive nature of graph algorithms allows for more natural and efficient exploration of complex, interconnected data relationships.
Conversely, employing these algorithms in relational databases necessitates converting data into tables that delineate relationships between objects, followed by the execution of algorithms in SQL or the integration of open-source libraries. This method becomes cumbersome and potentially inadequate for comprehensive analyses with large data volumes. The lack of native support for recursion in SQL further complicates matters, often resulting in less efficient and more difficult-to-maintain solutions.
DataWalk's approach leverages the power of graph algorithms directly on the data structure, providing a more intuitive, efficient, and scalable solution for complex analytical tasks.
Machine-Readable Knowledge
Knowledge graphs excel in providing machine-readable data, which is crucial for enabling automated systems and applications to process and understand information efficiently. This machine-readability stems from the structured, semantic nature of knowledge graphs, which encode data in a way that machines can easily interpret and utilize. By representing data with clear semantics and relationships, knowledge graphs facilitate interoperability and integration across various systems and platforms. In contrast, while relational databases are optimized for fast query execution and efficient data retrieval, they often require additional processing to translate data into a format that machines can fully comprehend and leverage for advanced reasoning. Consequently, knowledge graphs empower advanced applications such as artificial intelligence and machine learning by providing them with rich, structured data that can be readily analyzed and acted upon.
Summary
The DataWalk Knowledge Graph aligns closely with human cognitive processes, presenting data that intuitively mirrors how we perceive objects and their relationships in the real world. Thus, organizations can utilize the DataWalk knowledge graph to store their complex organizational knowledge in an accessible format, facilitating seamless knowledge transfer across departments and to new team members. Additionally, DataWalk is a platform that allows, without technical knowledge, a deep dive into data and conclusions. This approach contrasts with the structured, table-centric model of relational databases, which often requires a more technical mindset to navigate and understand complex relationships.
Solutions
Product
Partners
Company
Resources
Quick Links