
What Is Context?
Key Takeaways
- Context is the surrounding information that changes how something should be understood and acted on.
- Meaning tells you what something is. Context tells you what to do with it, in this situation, right now.
- Humans carry context automatically, assembled from memory, relationships, timing, and experience; implicitly and continuously. Machines require context to be explicitly structured, retrieved, maintained, or supplied.
- Digital systems are effective at storing data and encoding definitions. They have historically been poor at capturing the relational, temporal, and situational information that constitutes context.
- Context has become a critical concern because AI systems are no longer just answering questions. They are taking actions. Actions require context that data alone cannot supply.
- Knowledge graphs, semantic models, entity resolution, and unstructured data processing are the primary technical approaches to making context machine-readable.
What Is Context in Simple Terms?
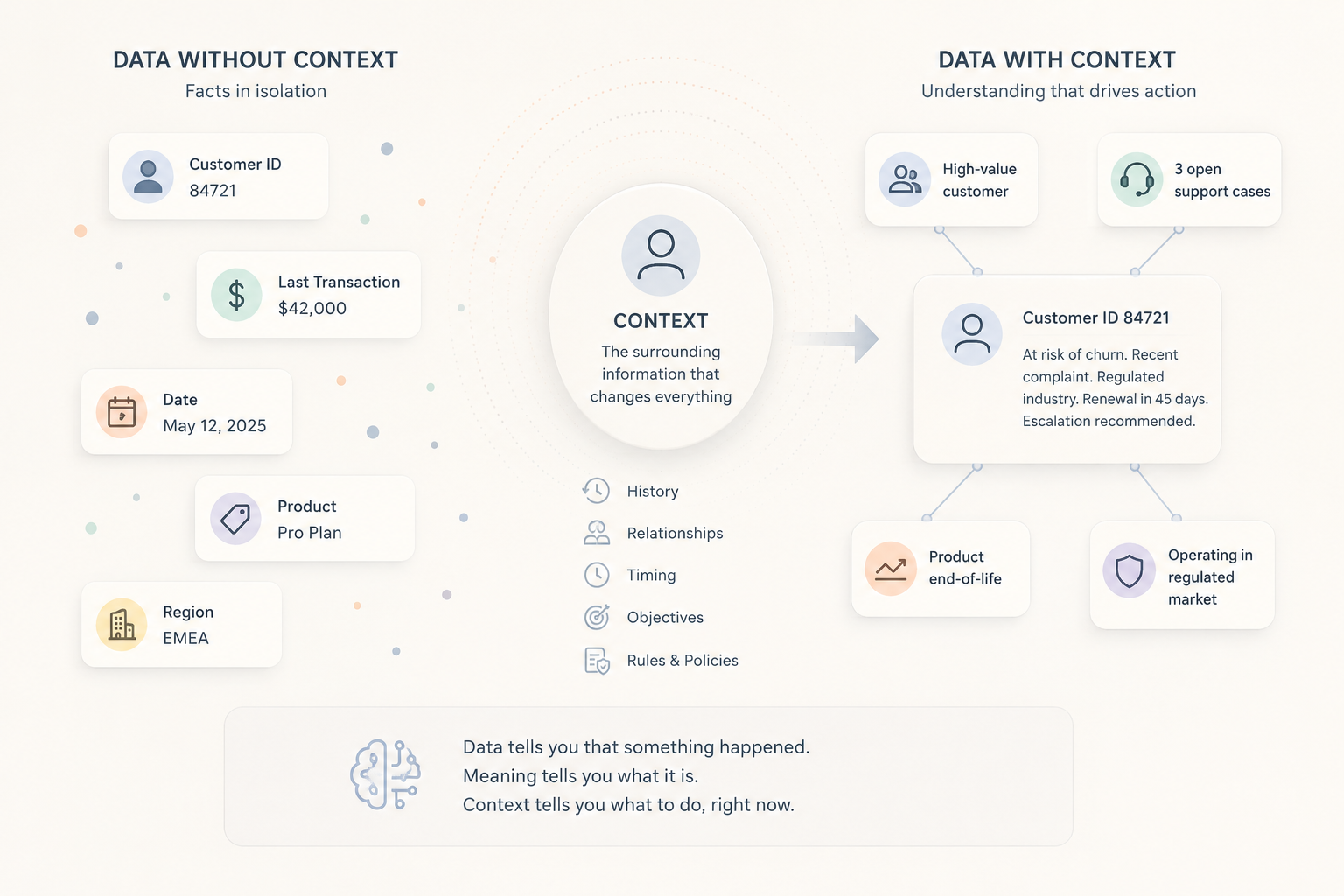
The word “context” comes from the Latin contextus, meaning “connection” or “weaving together.” That etymology is accurate: context is what weaves individual facts into something actionable. Without it, a fact sits alone. With it, a fact connects to other facts, to history, to relationships, and to the rules that apply in a particular situation.
Context is the extra information that explains what something means in the moment. The underlying data stays the same. What changes is how it should be interpreted.
Context and meaning are related, but they are not the same thing. Meaning is the definition of something. It is relatively stable. Context explains what that thing means right now, given everything else happening around it. The table below shows how data, meaning, and context differ.
| Data | Meaning | Context | |
|---|---|---|---|
| What it is | Raw recorded facts: numbers, names, events, timestamps | The definition of what something is: its category and type | The surrounding information that determines how something should be interpreted in a specific situation |
| What it tells you | That something happened | What a thing IS | What a thing means here, now, in relation to everything else |
| Example ("customer") | Record ID 84721, account type: enterprise, last transaction: $42,000 | A customer is a person or organization that has purchased a product or service | High-value customer, recently filed a complaint, linked to three open support cases, operating in a regulated market, on a product approaching end-of-life |
| Changes by situation? | No | No | Yes: context is always relative to a situation, a moment, and a question being asked |
| Sufficient to act on? | Rarely | No | Yes: when context is complete, a decision or action can follow |
The “changes by situation?” row matters because it highlights the core difference between data, meaning, and context. Data stays fixed. Definitions are relatively stable. Context changes depending on who is asking, what else is happening, and what decision needs to be made. That constant shifting is also what makes context difficult for machines to handle.
How Ally Built a Modern Fraud Intelligence Platform
Learn how Ally applied graph analytics and contextual investigation tools to uncover complex fraud networks and strengthen fraud prevention.
Read Case Study
Why is context easy for humans?
Humans carry context naturally. When a customer service representative answers a call, they do not build an understanding of the customer from scratch. They remember previous interactions and unresolved issues. They pick up on tone and realize the customer is frustrated. They apply the rules that matter for that account and situation. They may even recognize that the customer is connected to a larger group or ongoing issue. Even the act of calling support provides context. Most of this happens automatically and within seconds. That understanding usually comes from a mix of:
- Memory: what has happened before
- Relationships: who or what this connects to
- Timing: whether something is recent, recurring, or overdue
- Objectives: what the other person is trying to achieve
- Rules: what policies or obligations apply
Humans do not consciously assemble this information step by step. We absorb and apply it automatically through experience. That is why human judgment can sometimes look like intuition. Much of what we call intuition is actually context being applied very quickly.
Why is context hard for machines?
For decades, enterprise systems were designed to store and move data efficiently. The surrounding context (relationships, history, rules, situational meaning) was left to humans to supply. The problem is not a lack of data. Most systems were never designed to capture context in a way machines could use.
Before an analyst can begin work, they typically spend time pulling records from multiple systems, reconciling inconsistencies, and establishing who the relevant entities are and how they relate. That time is not analysis. It is context recovery.
The problem is compounded by the volume of data that exists outside structured records. Gartner estimates that unstructured data represents 80 to 90 percent of all new enterprise data and is growing three times faster than structured data. Documents, emails, call recordings, contracts, and case notes are where much of the context actually lives. That content is rarely connected to the structured records it relates to, which means the relational picture machines need to act intelligently is fragmented by design.
Context is not static. A transaction that appears normal in one moment may become suspicious when viewed against later activity, newly discovered relationships, or changing business conditions. That dynamic quality is part of what makes context difficult to engineer. Context must be continuously updated as relationships, behaviors, and conditions change.
Why does context matter so much right now?
It’s not just this moment, context has always mattered. What changed is what machines are being asked to do with and without it.
For most of the history of enterprise software, AI and analytics systems were answering questions. When AI assists human decision-making, a context gap is a friction: it slows things down, or produces an answer that needs correction. A human reviews the output, applies judgment, and decides.
Agentic AI changes the calculation. AI Agents do not answer questions. They take actions: routing a payment, flagging a transaction, approving an application, sending a communication. Those actions happen at machine speed, without a human review step, and with consequences that may be difficult or impossible to reverse. When an AI agent acts without context, the failure is not a wrong answer on a dashboard. It is a wrong action in the world.
That’s why Context Engineering has become something you can’t avoid in this domain. In October 2025, Gartner declared that “context engineering is in, and prompt engineering is out,” (1) advising AI leaders to prioritize context-aware architectures over clever prompting. AI researcher Andrej Karpathy, a founding member of OpenAI, described the underlying challenge as “the delicate art and science of filling the context window with just the right information for the next step.” (2)
For years, humans supplied missing context manually. AI agents exposed how much of that understanding was never actually inside the system. More and more, systems are being designed around supplying AI with the right context at the right moment. The pattern is becoming difficult to ignore: many AI failures are not model failures at all. The models are often capable. The missing piece is the surrounding understanding needed to act correctly.
Where does context come from in digital systems?
Different fields use the term “context” differently. In AI systems, it often refers to the information available to a model at inference time. In enterprise architecture, it refers more broadly to the connected situational understanding surrounding data and decisions. The two are related: one depends on the other. A model can only act on the context it receives, and the quality of that context depends on how well an organization has assembled and maintained it.
The components that together constitute machine-readable context include:
- Identity resolution: confirming that the customer in the CRM and the complainant in the ticketing system are the same entity
- Relationships: the connections between entities such as accounts linked to groups, transactions linked to counterparties, and individuals linked to organizations
- History: what has happened before, including prior interactions, resolved and unresolved issues, and behavioral patterns over time
- Business rules: the policies, thresholds, and obligations that determine what a given situation requires
- Temporal signals: timing indicators such as whether something is recent, recurring, or anomalous, and whether a threshold is about to be crossed
- Unstructured content: the text-based records where much organizational knowledge actually lives, including notes, contracts, emails, and case logs
- Semantic models: formal representations of what entities are and how they relate, allowing machines to infer meaning from structure
- Knowledge graphs: the architectural structure that holds these components together as a connected, queryable whole
Most systems rebuild context every time a new question is asked. Increasingly, organizations are realizing context itself may need to persist as a maintained layer rather than being reconstructed for every question.
In AI systems, context often means the information available to a model at inference time. In enterprise systems, it refers more broadly to the connected situational understanding surrounding data and decisions. The two are related.
No single database type does all of this on its own. Relational databases store structured records efficiently but treat relationships as something to be joined at query time rather than maintained directly. Document stores hold unstructured content but do not connect it to structured records. Knowledge graphs are designed specifically to hold the connected structure context requires: entities, their attributes, their relationships, and the rules governing them.
Building a context layer means assembling and maintaining the connected structure that machines need to act intelligently: resolved entities, mapped relationships, business rules, history, and unstructured content. That layer is not a byproduct of storing data well. It has to be built deliberately, kept current, and governed as a first-class asset. Gartner's Intelligence Capabilities Framework (3) identifies context as a distinct architectural layer and warns explicitly against accumulating 'context debt'; the loss of understanding not only of what happens but why. Among the technologies Gartner names for this layer, knowledge graphs carry a structural advantage: because relationships are maintained directly rather than reconstructed at query time, the architecture grows more useful as it expands rather than harder to change.
Learn more about context from DataWalk
What is Contextual Analytics. How Data Contextualization and Persistent Context Help Organizations Stop Rebuilding Intelligence from Scratch - https://datawalk.com/what-is-contextual-analytics/
Sources:
1. Gartner. "Lead the Shift to Context Engineering as Prompt Engineering Fades." Gartner document ID 6781234. October 2025. gartner.com/en/articles/context-engineering2. Karpathy, Andrej. Post on X (formerly Twitter). June 2025. x.com/karpathy
3. Carlie Idoine, "D&A Leaders Need an Architecture Framework to Realize AI Value at Scale," Gartner, G00842166, 4 March 2026.


Dr. Michael O’Donnell is a Senior Analyst covering data management strategy, with a particular interest in the gap between data and business value. He tracks the full stack (converged platforms, semantic enrichment, knowledge graphs, data products) is interested in what each gets right, where it stops short, and what that pattern keeps revealing. His measure is simple: can the person who needs the answer get it without an engineer in the middle.
ContactFAQ
The challenge was never the idea itself. The challenge was adoption, complexity, and incentives. Building and maintaining semantic models required significant effort, while most organizations were still focused on reporting, storage, and transactional systems rather than AI-driven reasoning.
What changed is that modern AI systems now expose the cost of missing context much more directly. For years, humans compensated for disconnected systems manually. AI agents cannot. That has renewed interest in many of the same ideas the Semantic Web was trying to address: connected data, shared meaning, entity relationships, and machine-readable context.
Join the next generation of data-driven investigations:
Discover how your team can turn complexity into clarity fast.
Solutions
Product
Partners
Company
Resources
Quick Links