
What is a Context Layer, in simple terms?
Key Takeaways
- Gartner's Intelligence Capabilities Framework positions the context layer as a distinct architectural tier, sitting between the data layer and the intelligence layer. It acts as a translation layer that helps make enterprise data usable and governable for AI systems.
- A context layer maintains and exposes business meaning, relationships, rules, governance policies, and history. It does not rebuild these from scratch on every query.
- The term is used differently across communities. Data governance teams, AI engineers, and enterprise architects all use it and often mean something slightly different. What they share is the same underlying need: a persistent, governed layer of context that AI systems can rely on.
- A context layer is distinct from a semantic layer. A semantic layer standardizes definitions for human analysts and BI tools. A context layer is designed to deliver governed, current context to AI agents taking actions.
- Gartner defines context debt as the loss of understanding of not only what happens in a process, but why. When context is never formally captured, every AI query pays the cost of reconstructing it.
- Many enterprise AI failures are not caused by weak models. They are caused by missing or fragmented context around the data the model is reasoning over.
What is a context layer?
Data is the record. Context is the meaning.
A payment transaction, for example, is just a recorded event until it is connected to the customer, account history, device, location, and surrounding activity that explain what it actually means. A context layer preserves those relationships and interpretations so systems and people can reason against connected business reality rather than isolated data points.
The context layer is an emerging architectural pattern designed to maintain and deliver business meaning, relationships, governance rules, operational state, and historical understanding to AI systems at runtime. Gartner’s Intelligence Capabilities Framework (ICF) positions it as a distinct architectural tier sitting between the information layer and the intelligence layer.(1)
Unlike traditional retrieval systems, a context layer is not rebuilt from scratch on every query. It maintains a governed and connected structure that persists over time, allowing AI systems to reason against current organizational context rather than isolated fragments of data. In this sense, persistent context is not a separate architecture, but a property of a well-maintained context layer.
The term is used differently across the industry. AI engineers often use it to describe the systems that assemble relevant information for agents at runtime. Data governance teams may think of it as an active metadata and policy layer. Enterprise architects increasingly describe it as a broader architectural capability that combines semantic structure, governance, memory, relationships, and operational reasoning.
These perspectives differ, but they describe the same underlying need: a maintained layer of organizational context that AI systems can reliably draw from.
There is no single agreed implementation of a context layer today. Different architectures combine semantic models, metadata systems, knowledge graphs, retrieval pipelines, policy engines, and memory frameworks in different ways. What they share is the goal of making organizational context persistent, governable, and reusable across systems and AI workflows.
The table below shows where a context layer sits relative to two concepts it is frequently confused with.
| Context Layer | Semantic Layer | Retrieval-Augmented Generation (RAG) | |
|---|---|---|---|
| What it is | An architectural tier that maintains business meaning, relationships, rules, history, and governance for AI systems | A translation layer that standardizes how business terms and metrics are defined across tools | A technique for retrieving relevant documents and injecting them into an AI model at query time |
| Primary job | Deliver governed, current, connected context to AI agents so they can act reliably.Maintain operational business context across systems | Ensure a term like "revenue" means the same thing in every dashboard and report. Standardize metrics and business definitions | Ground AI responses with relevant text at runtime. Retrieve relevant content for a prompt |
| Persistent or rebuilt each time? | Persistent, maintained as a live structure | Persistent but static. Traditional semantic layers are primarily designed for stable business definitions rather than dynamic operational context | Rebuilt at query time |
| Tracks changes over time? | Yes. Maintains historical state, changing relationships, and validity periods | Limited | No |
| Key limitation | Requires reliable entity resolution and governed data | Depends on stable business definitions and curated metrics | Depends on retrieval quality and source relevance |
How Ally Built a Modern Fraud Intelligence Platform
Learn how Ally applied graph analytics and contextual investigation tools to uncover complex fraud networks and strengthen fraud prevention.
Read Case Study
Why does context need its own layer?
Context needs its own layer because AI systems cannot inherit institutional understanding by default, without encoding. Human organizations operate on context that rarely exists in a formal system. Analysts, investigators, operators, and managers carry institutional understanding with them: which systems are trusted, when exceptions apply, how policies are interpreted in practice, and what historical events matter when making a decision.
Traditional enterprise systems were designed primarily to store and retrieve records efficiently. The broader situational understanding humans rely on was often reconstructed manually at the point of analysis rather than maintained directly inside the system itself.
AI systems do not inherit that institutional understanding automatically.
A model can process language and identify patterns, but it cannot infer an organization’s internal logic, historical reasoning, or operational constraints from raw enterprise data alone. When that context is not formally maintained in a machine-readable way, every AI query pays the cost of reconstructing it.
Gartner refers to this growing organizational problem as context debt: the loss of understanding not only of what happens in a process, but why.
The operational consequence is fragmentation. Teams begin solving context problems locally for individual agents, copilots, workflows, or departments. Each implementation creates its own definitions, rules, retrieval logic, and operational assumptions. Over time, organizations accumulate isolated “context islands” that cannot easily interoperate or explain decisions consistently across systems.
The context layer is emerging as an architectural response to this problem. Its role is not simply to retrieve information, but to maintain trusted organizational meaning and operational continuity across systems, workflows, and AI interactions.
What does a context layer contain?
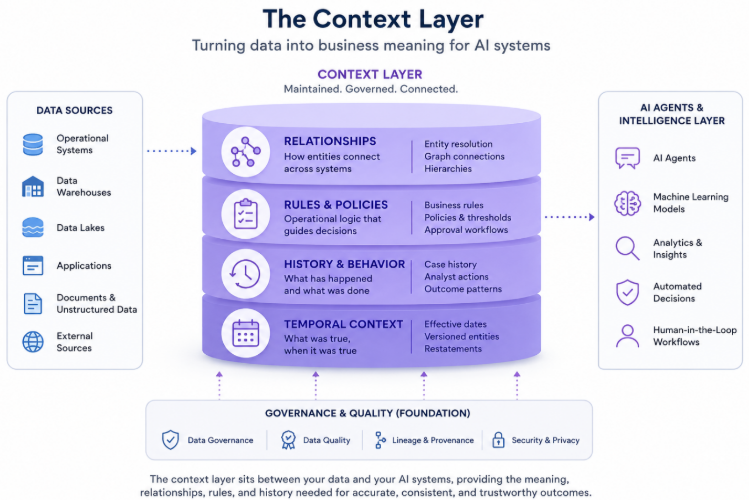
Gartner's Intelligence Capabilities Framework identifies four capability groupings in the context layer: metadata management, semantic reasoning, knowledge graphs, and a metrics store. In practice, these map to four types of context that a well-built layer holds and maintains.
- Structural context covers the definitions, entity relationships, and hierarchies that give data its shape. For example, who is connected to whom. Which entities belong to which categories. How different data sources relate to each other.
- Operational context covers the rules, procedures, policies, and decision logic that govern how data should be interpreted and acted on. Which thresholds apply. What a compliance rule requires. When an exception is permitted and when it is not.
- Behavioral context covers usage patterns and decision history. Which queries analysts actually run. How similar cases were resolved in the past. What worked and what did not. In a financial crime investigation, for example, this includes which entity combinations previously triggered escalation, and which were cleared, and why. This is the institutional memory that typically lives in people's heads and nowhere else.
- Temporal context covers change over time. What was true at a given point. When a rule was updated. Which version of a definition applied to a past decision. Without temporal context, AI systems reason from a snapshot when they need a timeline.
Together these four types of context are what allow an AI system to do more than retrieve a record. They allow it to interpret one.
Gartner's ICF describes context this way: "Context captures business meaning, relationships, rules and metadata that define intent, purpose and how actions tie back to specific goals and objectives."
Why do AI agents need a context layer?
Foundation models do not inherently possess durable organizational memory, operational understanding, or awareness of enterprise-specific rules. They reason primarily from the information made available to them at runtime. For simple one-off interactions, that limitation is manageable. For AI agents taking consequential actions across enterprise systems, it becomes a reliability problem. It helps to separate three concepts that are frequently blended together:
- Prompts tell the model what to do.
- Retrieval-augmented generation (RAG) retrieves relevant information dynamically at query time.
- A context layer governs the broader organizational meaning surrounding that information: whether it is current, trusted, connected, policy-compliant, historically valid, and operationally relevant to the decision being made.
RAG can be one component of a broader context architecture, but retrieval alone does not maintain durable organizational state, relationships, or operational continuity across systems and workflows.
Without maintained context structures, AI systems become significantly more prone to hallucination, inconsistency, and operational drift. Multi-step workflows lose continuity. Similar requests produce conflicting outcomes. Agents struggle to explain why decisions were made because the surrounding business logic was never formally maintained.
The issue is often not model intelligence but contextual grounding.
A 2026 benchmark testing frontier AI models on enterprise data tasks found that structured semantic context improved accuracy more significantly than differences between the models themselves, with gains ranging from 17 to 23 percentage points. The determining factor was not simply model capability, but the quality and structure of the context available to the model at inference time.(2)
What are the challenges of building a context layer?
A context layer does not create organizational understanding on its own. It depends on accurate, connected, and governable underlying data.
The quality of the context delivered to AI systems is constrained by the quality of the systems feeding it. Fragmented identities, inconsistent records, stale data, poor lineage, weak governance, and unresolved entity relationships all limit the effectiveness of any context architecture built on top of them.
This dependency is explicit in Gartner’s Intelligence Capabilities Framework, where the information layer and context layer are tightly interconnected. Reliable context depends on reliable underlying information management.
The operational challenge is that context is not static.
Business rules evolve. Organizational structures change. Policies are updated. Data sources are added and retired. Entity relationships shift over time. Maintaining useful organizational context therefore requires ongoing governance and operational discipline rather than a one-time implementation project.
Ownership is often unclear as well. Data engineering teams, governance teams, enterprise architects, and AI engineering groups may all partially own different aspects of the context architecture without any single function being responsible for maintaining it end-to-end.
This frequently leads organizations back into the same fragmentation problem the context layer was intended to solve: multiple isolated implementations of business logic, retrieval systems, semantic structures, and operational rules distributed across projects and teams.
Neither a semantic layer nor a context layer eliminates the need for trusted source data underneath. The foundational work of data quality, integration, governance, and entity resolution remains essential. Context architectures amplify the value of good information foundations, but they cannot compensate for the absence of one.
Learn more about context from DataWalk
- Why Generative AI in Banking Requires a Persistent Context Layer — Why standalone generative AI and RAG pipelines produce hallucinations in banking environments, and how a persistent context layer eliminates that failure mode for auditable financial crime investigations.
- What Is Contextual Analytics? — How mapping enterprise data once to a flexible ontology creates persistent context that compounds across every new initiative, eliminating the rebuild trap that costs organizations intelligence each time a new question is asked.
- Context Changes Everything In Investigations. But Changes In Context Matter Most. — How persistent contextual intelligence, built on an ontology-first architecture, reduces administrative overhead and improves detection accuracy as context evolves in financial crime investigations.
- Grounding Large Language Models with Knowledge Graphs — How knowledge graphs supply LLMs with connected, relationship-rich organizational context, reducing hallucinations and making AI outputs factually grounded and auditable.
Sources:
1) Gartner, "D&A Leaders Need an Architecture Framework to Realize AI Value at Scale," Carlie Idoine, 4 March 2026, ID G00842166.
2) Semantic Layers for Reliable LLM-Powered Data Analytics: A Paired Benchmark of Accuracy and Hallucination Across Three Frontier Models," 2026, Own Your AI / arXiv.
3) Gartner, "D&A Leaders Need an Architecture Framework to Realize AI Value at Scale," Carlie Idoine, 4 March 2026, ID G00842166.


Dr. Michael O’Donnell is a Senior Analyst covering data management strategy, with a particular interest in the gap between data and business value. He tracks the full stack (converged platforms, semantic enrichment, knowledge graphs, data products) is interested in what each gets right, where it stops short, and what that pattern keeps revealing. His measure is simple: can the person who needs the answer get it without an engineer in the middle.
ContactFAQ
Persistent context, as a concept, refers to the maintained organizational layer that any agent or system can draw from: the business rules, entity relationships, governance policies, and history that exist independently of any single agent or session. It does not belong to one agent. It belongs to the organization.
An agent with persistent memory recalls your past interactions. A context layer with persistent context ensures the business meaning and rules behind those interactions are accurate, current, and governed. Both matter. One without the other leaves gaps.
Join the next generation of data-driven investigations:
Discover how your team can turn complexity into clarity fast.
Solutions
Product
Partners
Company
Resources
Quick Links