
What is an Ontology?
A practical guide for enterprise data and AI teams.
Key Takeaways
- An ontology is a formal, machine-readable model that defines what concepts mean, how they relate to each other, and what rules govern those relationships.
- Without a shared ontology, the same real-world entity appears under different names in every system: "customer" in one, "counterparty" in another, "subject" in a third.
- An ontology differs from a data model: a data model defines how one system stores information; an ontology defines what concepts mean across all systems.
- A knowledge graph without an ontology stores connected data but cannot enforce consistent meaning. The ontology is the schema; the knowledge graph is the populated instance.
- Ontologies enable inference: relationships never explicitly stored can be deduced from rules defined in the model.
- AI systems become more reliable when supported by ontologies, because structured relationships and governed definitions reduce semantic inconsistency in outputs.
Why are ontologies important right now?
The semantic web promised to make data understandable to machines. In 2001, the vision was clear: if we could describe what data actually means, not just store it, computers could connect the dots automatically. Standards emerged. Organizations invested in metadata, taxonomies, ontologies, and enterprise architecture initiatives intended to create shared meaning across systems.
The problem was not that the ideas were wrong. The problem was that the operational cost of building and maintaining semantic consistency often moved more slowly than the business itself. Systems changed faster than models could be aligned. Integration projects multiplied. Definitions drifted. Meaning remained fragmented across applications, spreadsheets, pipelines, and teams.
AI is now making that fragmentation harder to tolerate. Large language models and reasoning systems depend on consistent definitions, governed relationships, and connected context to produce reliable outputs. The underlying problem never disappeared. AI simply made it operationally unavoidable.
How Ally Built a Modern Fraud Intelligence Platform
Learn how Ally applied graph analytics and contextual investigation tools to uncover complex fraud networks and strengthen fraud prevention.
Read Case Study
What does "ontology" mean in data systems?
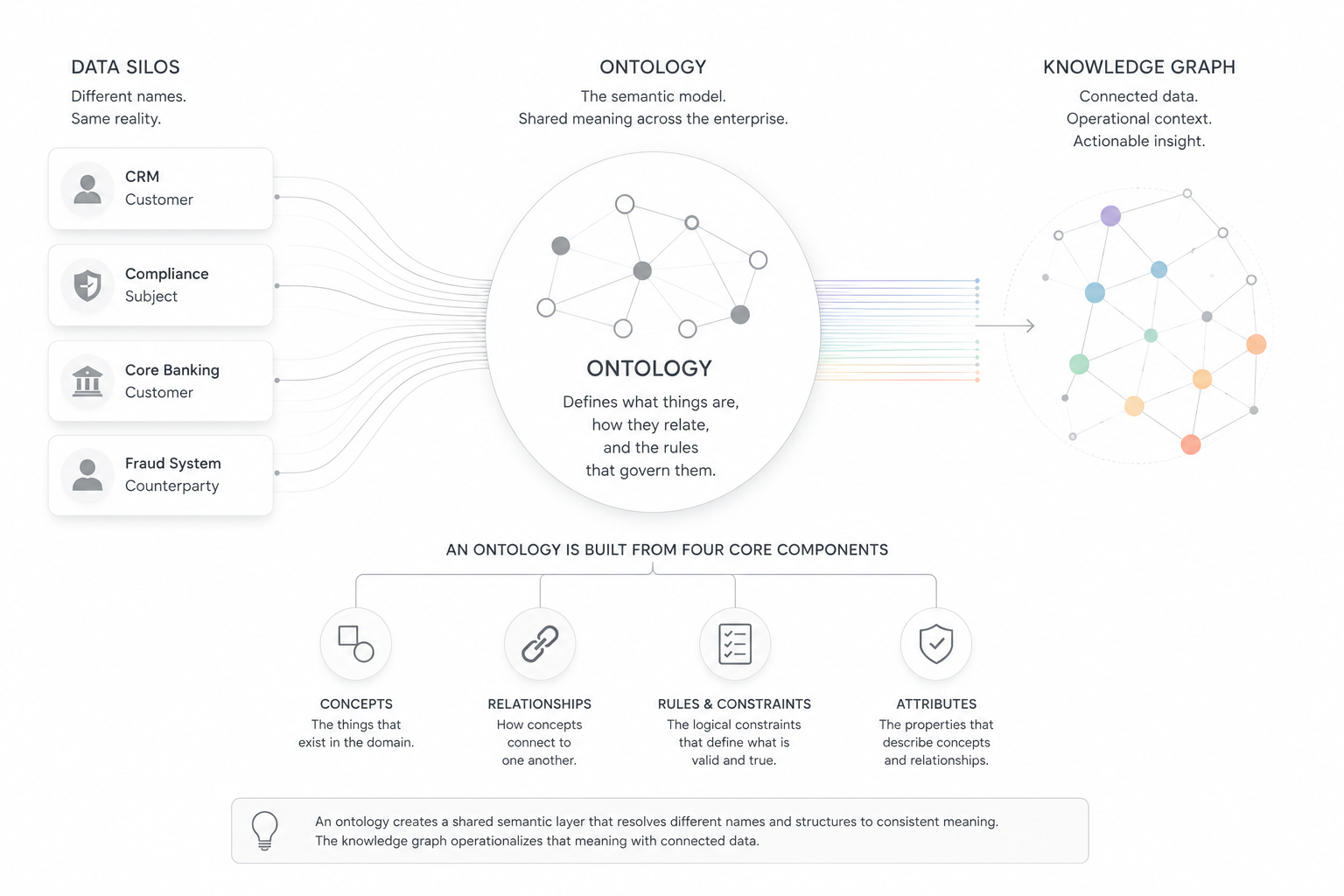
An ontology is a formal, machine-readable model of a domain. It defines the categories that exist within that domain, the properties that describe them, and the rules governing how they relate to each other. In data systems, an ontology answers not "where is this data stored?" but "what does this data mean, and how does it connect to everything else?"
The term comes from philosophy, where it referred to the study of existence and being. Computer science borrowed it to describe something more practical: a structured framework for representing knowledge in a way that machines can interpret consistently across systems. The philosophical roots explain the name; the enterprise use case explains why it matters.
An ontology contains three core components:
- Classes: the categories of things that exist in the domain (Person, Organization, Account, Transaction)
- Properties: the attributes that describe those classes and the relationships between them (Person "owns" Account; Account "belongs to" Organization)
- Axioms and rules: the logical constraints that govern valid relationships (a Transaction must involve at least two Accounts; a Person classified as a Beneficial Owner must be linked to an Organization)
Why does shared meaning break down in enterprise systems?
Traditional enterprise systems were built to store and retrieve records efficiently. They were not designed to preserve meaning across system boundaries.
Consider one real-world entity: a person who holds a bank account. In a core banking system, that person is a "customer." In a fraud detection platform, the same individual is a "counterparty." In a compliance system, they are a "subject." Each system is internally consistent. None of them agree with the others.
When an organization adds more applications, data pipelines, and AI systems, the cost of reconstructing meaning at every integration point compounds. Analysts reconcile terminology manually. Pipelines fail when field names change. AI models trained on one system's data fail to generalize across others because the underlying concepts were never aligned.
This is the problem an ontology solves. It establishes a shared semantic layer: one place where "customer," "counterparty," and "subject" resolve to a single canonical concept with defined attributes and relationships. The translation happens once. Every downstream system benefits from it.
Importantly, the ontology does not replace underlying systems. The CRM, fraud platform, compliance application, and warehouse continue operating independently. The ontology creates a shared semantic layer above them, allowing data from different systems to resolve against common meaning without forcing every platform into the same schema.
How does an ontology differ from a data model?
This is the question most enterprise architects ask first. The short answer: a data model is designed around how a specific system stores and processes information; an ontology is designed around what concepts mean across systems.
A conceptual model clarifies requirements for one bounded system. A logical model normalizes those requirements for implementation planning. A physical model specifies how data is stored in a particular database. Most traditional data models are scoped around specific applications, databases, or bounded operational contexts.
An ontology operates at a different level. It creates a stable meaning layer that spans multiple systems, persists through technology changes, and supports reasoning about relationships that were never explicitly programmed.
Comparison: data models vs. ontology
| Conceptual data model | Logical data model | Physical data model | Ontology | |
|---|---|---|---|---|
| What it represents | Business entities for one system | Normalized structure for implementation | Storage-specific schema | Semantic concepts across systems |
| Machine-readable? | No | Partially | Yes | Yes |
| Supports reasoning? | No | No | No | Yes |
| Cross-system? | No | No | No | Yes |
| Handles inference? | No | No | No | Yes |
The practical consequence: without an ontology, every system integration becomes a translation exercise. With one, that translation happens once at the semantic layer and every downstream query inherits it.
Why does a knowledge graph need an ontology?
A knowledge graph without an ontology stores connected data. It does not necessarily store understood data.
Without a governing ontology, different teams model the same real-world relationships differently. One team connects Person to Account with a "has" edge. Another uses "owns." A third uses "controls." Querying across those teams produces inconsistent results, and no automated system can reconcile them reliably without a governing semantic model.
An ontology defines which relationships are semantically valid and what they mean. It creates the consistency that allows a knowledge graph to support reasoning, not just retrieval. It also enables inference: if the ontology defines that a Beneficial Owner controls an Organization, and that Organization holds an Account, a system that understands the ontology can infer the link between the Beneficial Owner and the Account without that link being explicitly stored.
The ontology provides the semantic model governing the graph. The knowledge graph is the populated instance of that schema, operating against real data. One without the other produces either a rigid structure with no data or a flexible store with no consistent meaning.
Do you need an ontology to build a knowledge graph? No. But without one, you are building a store of connections, not a system of meaning. The reasoning, inference, and cross-system consistency that make a knowledge graph genuinely useful all depend on it.
How do ontologies affect AI and machine learning systems?
Many enterprise AI systems produce more reliable outputs when grounded in structured, governed meaning. Without it, a model trained on data from one system may generalize poorly to another because the same concept is represented differently in each source.
Relationship-centric AI workloads benefit from explicitly modeled relationships. In relational systems, relationships are reconstructed during query execution through joins. In knowledge graphs, those relationships are stored directly and traversed explicitly.
That distinction matters for investigative, contextual, and reasoning-heavy workloads where the connections between entities are often as important as the entities themselves.
Ontologies contribute to AI reliability in three ways;
- they reduce semantic inconsistency: when all source data maps to the same conceptual layer before a model processes it, the model encounters fewer conflicting representations of the same thing.
- they support explainability: a system grounded in an ontology can trace why a particular relationship was inferred, not just report that it was.
- they improve the stability of outputs over time, because the governing definitions are explicit, manageable over time, and no longer exist only implicitly inside training data.
This is particularly relevant for large language model deployments over enterprise data. An LLM that queries a knowledge graph without a governing ontology is querying a structure whose relationships may be inconsistently defined. An ontology gives the model a reliable framework to work within. Connections alone are not enough. Enterprise systems routinely contain multiple relationship types that appear similar but carry very different meaning operationally, legally, or analytically. An ontology defines which relationships are valid, how they differ, and what rules govern them.
As organizations deploy AI agents against enterprise data, ontologies are increasingly becoming part of a broader contextual architecture. The ontology provides governed semantic structure. The knowledge graph operationalizes connected data against that structure. Together, they create a persistent layer of organizational meaning that AI systems can reason against over time.
What types of ontologies are used in enterprise practice?
Three types are relevant for most organizations:
- Domain ontologies model a specific subject area: financial crime, healthcare, logistics. They define the concepts and relationships relevant to that domain and are the most common starting point for enterprise deployments.
- Enterprise ontologies span an organization's full data landscape, reconciling concepts across business units, systems, and data domains. They are broader in scope and longer to build, but they create organization-wide semantic consistency.
- Upper ontologies define the most general categories (Entity, Event, Relationship) and serve as a formal foundation that domain ontologies extend. They are less common in enterprise practice but appear in large-scale knowledge management and research applications.
Most organizations start with a domain ontology scoped to a specific use case, then extend it as integration requirements grow. The design of the ontology is typically the constraint, not the technology that implements it: ontology engineers with the domain knowledge and formal modeling skills required are in short supply.
Organizations also don't always start from scratch. Established open ontologies exist for major domains and can be adopted or extended rather than built from the ground up. In financial services, FIBO (the Financial Industry Business Ontology) is a widely referenced open standard covering financial instruments, legal entities, and market data. Starting from a published standard reduces the design burden significantly and provides a foundation that regulators and counterparties may already recognize.
Learn more about ontologies from DataWalk
- Ontologies and Knowledge Graphs: Making Enterprise Data Easy to Understand — A practical walkthrough of how ontologies function inside DataWalk, including how LLMs use ontology structure to query a knowledge graph effectively.
- Relational Model Database vs. The DataWalk Knowledge Graph — A direct comparison of relational data modeling and knowledge graph architecture, with a focus on how ontology-driven graphs handle complex real-world relationships.
- Grounding Large Language Models with Knowledge Graphs — How ontology structure enables LLM agents to traverse graphs, run queries, and deliver reliable outputs over enterprise data.
- Knowledge Graph Software — DataWalk's knowledge graph product page, covering the combined ontology, reasoning, graph, and AI capabilities in a single platform.


Dr. Michael O’Donnell is a Senior Analyst covering data management strategy, with a particular interest in the gap between data and business value. He tracks the full stack (converged platforms, semantic enrichment, knowledge graphs, data products) is interested in what each gets right, where it stops short, and what that pattern keeps revealing. His measure is simple: can the person who needs the answer get it without an engineer in the middle.
ContactTable of contents
- Key Takeaways
- Why are ontologies important right now?
- What does "ontology" mean in data systems?
- Why does shared meaning break down in enterprise systems?
- How does an ontology differ from a data model?
- Why does a knowledge graph need an ontology?
- How do ontologies affect AI and machine learning systems?
- What types of ontologies are used in enterprise practice?
- Learn more about ontologies from DataWalk
FAQ
Organizations also don't always start from scratch. Established open ontologies exist for major domains and can be adopted or extended rather than built from the ground up. In financial services, FIBO (the Financial Industry Business Ontology) is a widely referenced open standard covering financial instruments, legal entities, and market data. Starting from a published standard reduces the design burden significantly and provides a foundation that regulators and counterparties may already recognize.
When you map a schema to an ontology, something significant happens. A field that exists only inside one system acquires meaning that travels beyond it. Map five systems to the same ontology and a customer_id, a party_ref, and a subject_number resolve to the same real-world concept. The data stays where it is. The meaning becomes shared. DataWalk calls this Semantic Lift.
Join the next generation of data-driven investigations:
Discover how your team can turn complexity into clarity fast.
Solutions
Product
Partners
Company
Resources
Quick Links