
Bridging Reason and Reality: DataWalk’s Unique Hybrid Graph Reasoning for Enterprise AI
Introduction – Why Reasoning Matters for AI and Agentic Systems
Modern artificial‑intelligence (AI) systems are no longer confined to pattern recognition.Agentic AI – AI that can plan, adapt, and act autonomously – needs to understand context, evaluate evidence, and justify its decisions. Large‑language models (LLMs) excel at broad semantic understanding but struggle with multi‑hop reasoning, precise fact recall, and navigating enterprise‑specific relationships.
Knowledge graphs fill this gap by providing a machine‑readable network of entities, relationships, and context. They enable explicit reasoning: from high‑level rules to concrete conclusions. For agentic AI, this capability is crucial for tasks like investigating supply‑chain risks, identifying high‑risk counterparties, or aligning AI agents with internal policies. Inference – deriving new facts from existing data – ensures that AI systems do not just answer the explicit question but also surface implicit insights. In this article for technical experts, we explore how DataWalk, a hybrid graph analytics platform, delivers practical reasoning and inference to support enterprise AI.
Reasoning vs. Inference
Reasoning is the general process of drawing conclusions from existing knowledge. It may be deductive (deriving logically necessary conclusions), inductive (generalizing from examples), or abductive (finding the best explanation). Inference refers more specifically to computing and materializing new facts by applying a set of rules to explicit data. In knowledge‑graph literature, the terms are often used interchangeably, but it is useful to distinguish the two: reasoning is the design of rules and logic, whereas inference is the execution of that logic to produce new data.
Example:
We need to determine the Ultimate Beneficial Owner (UBO).
Reasoning (design):
“Ownership propagates through shareholding. Multiply percentages along each path, then sum over all disjoint paths. A UBO is detected when the total ownership reaches or exceeds a 25% threshold.”
Inference (execution):
The engine computes:
A owns 80% of B; B owns 40% of C; therefore, A owns 32% of C.
Since A holds ≥25% in C, A is identified as a UBO. This is recorded as both a fact and its lineage.
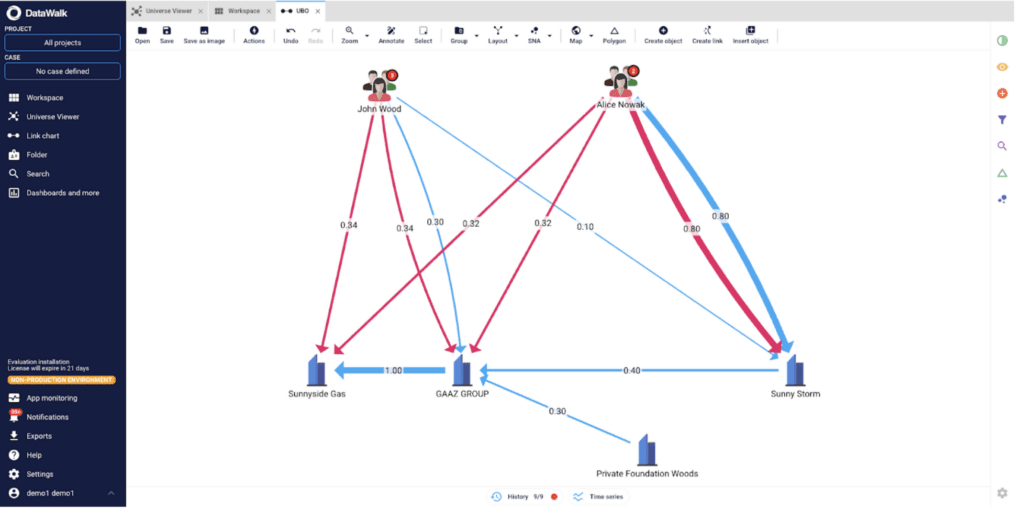
Figure 1 – An example of an inference for shareholders' network.
Per Figure 1, above, consider a network of companies and individuals where we want to identify a company's ownership. Each direct shareholder has an associated value (between 0 and 1) based on the percentage of their beneficial share. The goal is to assess an entity’s ownership not only from its direct connections (blue) but also from indirect relationships (red) using inference algorithms that multiply and add shares. Because Alice owns 80% of Sunny Storm directly, she indirectly owns 32% of GAAZ Group and 32% of Sunnyside Gas.
Graph Models and Reasoning: RDF vs. Property Graphs
Semantic Knowledge Graphs (RDF)
In general, there are two types of graphs. The Resource Description Framework (RDF) expresses information as triples (subject–predicate–object). Combined with the Web Ontology Language (OWL), RDF enables the definition of implicit classes, properties, and axioms. OWL reasoners can automatically infer that a person who likes food is a food lover, even if that triple is not explicitly stored. RDF’s atomic decomposition and globally unique identifiers make it particularly well-suited for ontology‑based inference and cross‑domain data sharing. However, RDF triple stores are often verbose and less efficient for path‑heavy queries; adding metadata may require additional triples, which can increase storage and slow down traversals.
Property‑Graph Databases
Property‑graph databases (Labeled Property Graphs or LPGs) store data as nodes and edges with key‑value properties. They were created to optimize deep‑graph traversal and query performance, prioritising speed and flexible schema over strict semantics. Graph databases like Neo4j and TigerGraph handle billions of relationships with sub‑second traversals, making them a good fit for fraud detection, recommendation engines, and social‑network analytics. However, flexibility comes at a price: LPGs do not enforce a formal schema or ontology; nor do they provide native reasoning based on class inheritance or transitive properties. Developers must implement reasoning manually (e.g., adding additional labels) or rely on plug‑ins; the Neosemantics extension for Neo4j allows simple inheritance, but complex OWL reasoning requires external reasoners.
Performance Trade‑offs
Because LPGs lack built‑in inference, users implement rules via custom traversals or separate processes. This works for modest datasets, but inference over very large property graphs can become cumbersome, as each reasoning task requires scanning and computing across relationships. While graph databases like Neo4jTM and TigerGraphTM excel at handling connected data, they lack advanced inference capabilities. This white paper notes that many graph platforms, designed for static datasets, struggle with deep traversal under pressure and may introduce latency when reasoning‑based workloads require shared‑memory logic. This underscores the need for platforms that combine high‑performance traversal with built‑in reasoning.
DataWalk: A Hybrid Knowledge Graph
DataWalk is an enterprise-grade analytics platform that blends the high performance of labeled property graphs (LPGs) with the semantic modeling flexibility typically associated with RDF. At its core, DataWalk uses a hybrid operational ontology architecture. This design stores data in a property-graph-like engine while maintaining a distinct ontology layer that defines classes, attributes, and logical rules. This enables dynamic inference, multi-hop traversals, and semantic enrichment without compromising performance.
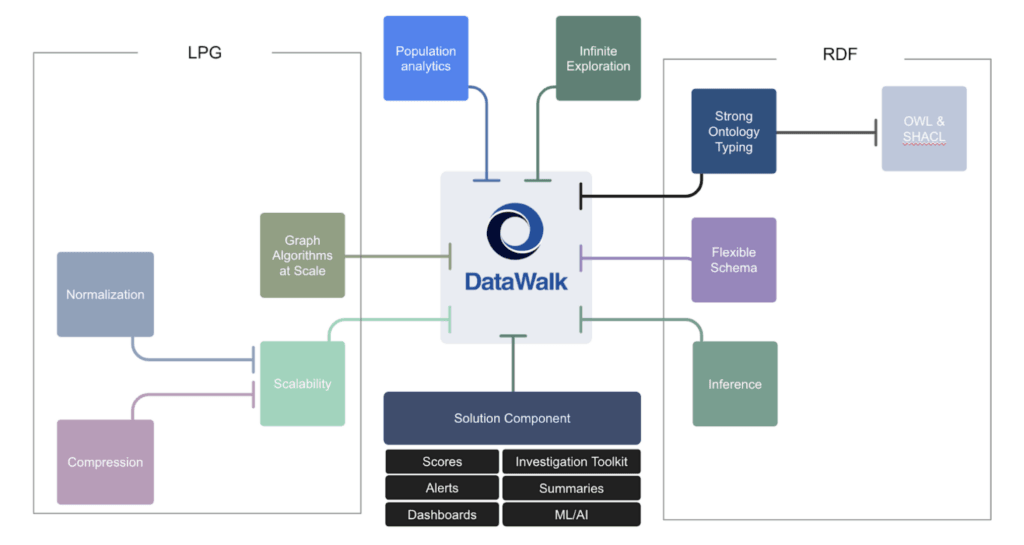
Figure 2: DataWalk offers the best characteristics of the labeled property graph and resource description framework worlds.
Unlike RDF triple stores that express knowledge using rigid subject-predicate-object triplets, or traditional LPGs where relationships are limited to edge-level properties, DataWalk introduces Connecting Sets: first-class relationship objects. These behave like direct edges for fast traversal, but also act as fully attributed nodes when needed—supporting metadata, audit trails, and even relationships to other objects or connections. This allows “links to links,” enabling advanced modeling scenarios (like responsibilities, transactions, or investigations) without sacrificing simplicity or requiring early schema decisions.
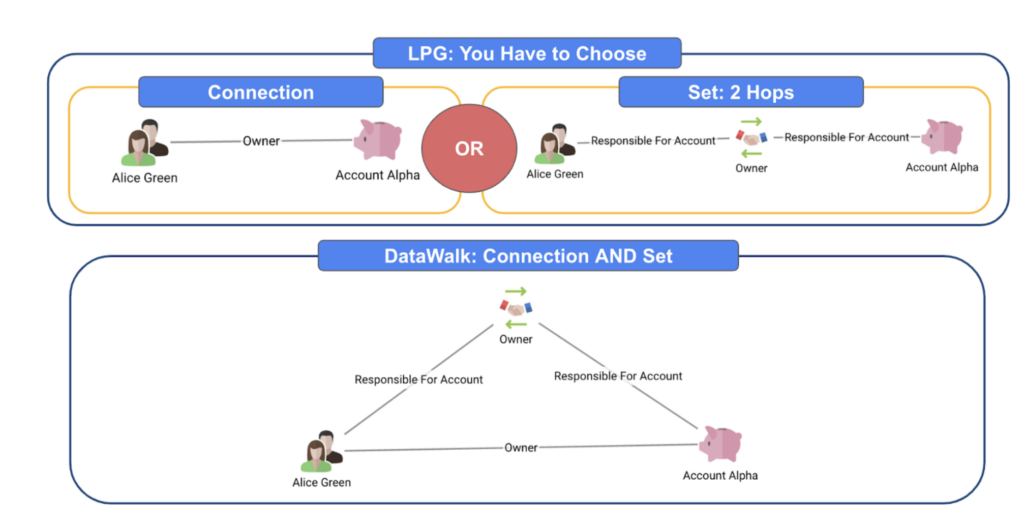
Figure 3: DataWalk allows links to links, acting like a connection and a set.
With this hybrid approach, DataWalk delivers the best of both worlds: the speed, scalability, and simplicity of LPGs, combined with the flexibility and semantic richness of RDF—without the operational complexity of either.
Graph Consistency Engine
At the heart of DataWalk’s inferencing capability is the Graph Consistency Engine (also referred to as the dependency refresh engine). This engine evaluates logical rules whenever data is added or changed and materializes newly inferred facts into the operational graph. Unlike lazy reasoning—where inference is evaluated dynamically at query time—DataWalk implements eager inference, meaning that derived facts are stored as first-class citizens in the database and are automatically refreshed whenever dependent data changes.
It is worth noting, however, that DataWalk also supports non-materialized inference when needed, allowing certain inferences to be computed on demand. This offers flexibility to balance performance and storage considerations depending on the use case.
This architecture ensures that dashboards, visualizations, and analytics always operate on a consistent, precomputed knowledge base. Notably, DataWalk’s inference engine does not require both sides of a relationship to be present simultaneously to derive and store results. It is designed to compute partial inferences when one side of a logical rule is satisfied, holding these intermediate results in the operational graph. When the missing counterpart arrives—hours, days, weeks, or even months later—the system completes the rule automatically. This design supports real-world analysis scenarios where information arrives gradually from disparate data sources.
For example, a saved analysis includes a query for finding all black cars with a license plate starting with 2P for residents within a four-block area. Several weeks later, data for an additional car arrives in the system, and the count in the analysis is updated automatically.
Rule Palette Components
The Graph Consistency Engine relies on a palette of rule mechanisms that can be combined to define complex inference logic:
Component | Purpose | Example |
|---|---|---|
Autoconnects | Establish relationships based on matching attributes across sets. | Create an “owns” link when two entities share a tax identifier or shareholding threshold. |
Virtual Paths | Define indirect relationships that traverse multiple hops. | A high‑risk entity inherits risk from entities it controls via shareholder chains. |
Calculated Columns | Compute values using expressions or SQL-like statements. | Calculate the total percentage of ownership or a risk score based on connected transactions. |
Analyses | Analyses persist in the system, and the objects are grouped together when the analysis is saved. | Count the number of suspicious transactions within three hops or run a community detection algorithm. |
Scoring | Assign risk or confidence scores based on model outputs and heuristics. | Compute a High‑Risk Score for an entity by aggregating risk indicators from its connections. |
App‑Center Apps | Deploy custom algorithms written in Python. | Implement a personalised propagation model or integrate an external AI model to classify entities. |
These components enable DataWalk to capture deterministic logic and more nuanced analytics. For instance, scoring rules can incorporate machine‑learning models, and App Center apps can implement advanced functions such as natural‑language processing or graph neural networks.
Implementing Semantic‑Web Inference Rules in DataWalk
Although DataWalk does not implement the full spectrum of OWL semantics, it supports a subset of semantic‑web inference rules crucial in operational analytics. The table below summarises these rules and how DataWalk materialises them.
Semantic‑Web Rule | Description | DataWalk Implementation |
Functional | A property has a unique value for a given subject (e.g., every employee has exactly one supervisor). | DataWalk enforces uniqueness via autoconnects and calculated columns; conflicting assignments trigger alerts or require manual resolution. |
Inverse | If two subjects share the same object via this property, they refer to the same entity (e.g., two records with the same tax ID represent the same company). | Autoconnect rules merge or link entities based on shared identifiers, supporting, e.g., entity resolution. |
Inverse | For a property P, another property Q is its inverse. (e.g., If Susie is the parent of Bob, then Bob is the child of Susie). | DataWalk creates reciprocal links automatically; updates to one direction propagate to the other via the Graph Consistency Engine. |
Symmetric | A property is symmetric. (e.g., if Susie has a friend Bob, then Bob has a friend Susie). | DataWalk materializes symmetric links for relationships like partnerships or peer connections. |
Transitive | A property is transitive: if A owns B and B owns C, then A owns C (e.g., ancestor relationships, ownership chains). | Virtual paths and autoconnects compute multi‑hop relationships; the Graph Consistency Engine materializes the transitive closure. |
DataWalk resolves other semantic rules during modelling. Cardinality (minimum or maximum number of relationships) and domain/range constraints are encoded in the schema and rule definitions; they are enforced at data load or rule definition time rather than through inference.
Considerations and Complementary Tools
DataWalk’s hybrid architecture balances performance and semantics. It is not a full OWL reasoner: it deliberately focuses on operational inference, where deterministic rules produce actionable facts and analysts can validate and override results. In enterprise AI, this pragmatic approach is often preferable to the strict but brittle description logic. However, users should be aware of the following considerations:
- Complex semantic reasoning – For applications that require comprehensive OWL reasoning or automated schema evolution, an external RDF triple store or description‑logic reasoner may be more appropriate. DataWalk can ingest such inferred data via its connectors and integrate it into the operational graph.
- Performance at scale – DataWalk’s graph engine is optimized for multi‑hop queries and rule execution. DataWalk handles even, very deep transitive closures and highly recursive rules, which challenge other graph databases. DataWalk addresses this by materializing inference and enabling parallel processing via its Graph Consistency Engine. Performance tests on platforms like TigerGraphTM highlight that many graph databases built for static datasets may struggle with deep traversal and reasoning at scale. Read our paper comparing the Find Paths algorithm run on DataWalk and TigerGraphTM to see how their scaling differs.
- Integration with Composite AI – Inference is one component of DataWalk’s broader Composite AI strategy, which combines rule‑based logic with machine‑learning models, natural‑language processing, and graph analytics. This enables DataWalk to tackle use cases like fraud detection, high‑risk party identification, and supply‑chain resilience by leveraging deterministic inference and probabilistic models.
- Extensibility and explainability – Advanced users can extend DataWalk through Python‑based App Center apps. These apps can implement domain‑specific algorithms, integrate external AI services, or perform complex computations. Because DataWalk materialises inferred facts, all results remain explainable; each inferred relationship or label has a traceable rule and data lineage.
Conclusions
Knowledge graphs are becoming indispensable for AI systems that require reasoning, explainability, and multi‑hop context. Traditional property‑graph databases offer high‑performance traversal but typically lack built‑in inference. RDF triple stores support rich semantics but can be verbose and slower for traversal. DataWalk bridges these worlds: it provides a hybrid operational knowledge graph that couples the speed and flexibility of property graphs with an ontology‑driven Graph Consistency Engine that materialises logical rules. This design allows enterprises to model hierarchies and inheritance manually, define custom inference logic, and implement advanced analytics via scorings and App‑Center apps.
In the era of AI assistants, agentic AI, and real‑time decision intelligence, inference is not optional. It is the mechanism that turns connected data into connected knowledge. By enabling inference at scale while maintaining performance, DataWalk empowers organisations to build trustworthy AI systems that can explain their reasoning and adapt to evolving data. This balance of reason and reality makes DataWalk’s approach unique in the landscape of graph technologies.


Kamil Goral is an expert in advanced graph analytics and AI reasoning, specializing in the design and implementation of scalable solutions for complex data relationships. His expertise encompasses hybrid graph architectures, ontology-driven inference, and ensuring explainability in enterprise AI systems.
ContactFAQ
Join the next generation of data-driven investigations:
Discover how your team can turn complexity into clarity fast.
Solutions
Product
Partners
Company
Resources
Quick Links